Markov Decision Processes and Dynamic Programming
The finite MDP, the Bellman expectation and optimality equations, and the gamma-contraction that makes value iteration and policy iteration converge — dynamic programming as the spine the rest of the curriculum returns to.
Markov Decision Processes and Dynamic Programming
Where we are. This is the first chapter, and it states the object the whole curriculum orbits: the finite Markov decision process and the two equations that pin down optimal behaviour in it. The claim is small and load-bearing — the optimal value function is the unique fixed point of a -contraction, and value iteration and policy iteration are two ways of reaching that fixed point. Everything later — LQR, MPC, model-based and model-free RL — computes, approximates, or learns this same fixed point when the MDP is too large, too continuous, or unknown.
Notation and conventions
We use the case convention of Sutton & Barto Sutton & Barto (2018) throughout: lowercase names a true object we want (), and uppercase names an estimate we hold and update ().
| Symbol | Meaning | |---|---| | | finite state and action sets; | | | dynamics — joint probability of next state and reward | | | policy — probability of action in state | | | discount factor (strict inequality is load-bearing) | | | state- and action-value functions of (true) | | | optimal value functions | | | the -th value iterate (an estimate of ) | | | Bellman expectation / optimality operators | | | sup norm on : |
A value function on a finite state set is a vector in , a point in -dimensional space. The operators below move that point around, and “solving the MDP” means finding the one point they hold still.
The finite Markov decision process
A Markov decision process is a controlled Markov chain: at each step the agent sees a state, picks an action, and the environment returns a reward and a next state, with the Markov property that the future depends on the past only through the current state.
A finite Markov decision process is a tuple with finite, discount , and dynamics
a probability distribution over for each . We write the state-transition kernel and expected reward as the marginals
The Markov property is the modelling commitment that earns us everything that follows: because the next state and reward depend only on , a value function needs only one argument — the current state — and the recursion below closes on itself. The canonical reference for the finite-MDP formalism and its solution methods is Puterman Puterman (1994) ; the founding treatment of the underlying optimization principle is Bellman Bellman (1957) .
A (stationary) policy is a distribution over actions for each state. Acting under produces a trajectory , and the discounted return from time is
Because rewards are bounded on a finite MDP and , the series converges absolutely, with where .
Value functions
A value function answers one question: starting here and acting under , how much discounted reward do I expect? The state-value fixes the starting state; the action-value also fixes the first action.
For a policy , the state-value and action-value functions are
where averages over trajectories generated by and . The two are linked by .
The Bellman expectation equation
Everything recursive about value functions comes from one move: split the return into the immediate reward and the discounted return from the next state, then condition on what happens in one step. That conditioning is the law of total expectation, the single most-used tool in RL theory.
For every policy and state ,
Start from the definition and peel off one step of the return, :
The Markov property is what licenses the last line: the expected return from onward depends on the past only through .
Read as a system of linear equations in the unknowns , the Bellman expectation equation defines . Collecting it into a single map on gives the operator we will iterate.
The Bellman expectation operator acts on a value vector by
where and . By Theorem 1.1, is a fixed point: .
In vector form with the transition matrix — an affine map, so its fixed point solves the linear system . We will use that closed form for policy evaluation below.
Optimality: the Bellman optimality equation
So far was fixed. Optimal control asks for the best achievable value, and — remarkably — a single policy attains it simultaneously in every state.
The optimal value functions are
the maxima taken pointwise over all policies. A policy is optimal if .
The optimal state-value function satisfies, for every ,
and a policy is optimal iff it is greedy with respect to — i.e. in each state it puts all mass on actions attaining the maximum.
We argue from Bellman’s principle of optimality Bellman (1957) , assuming for now that is well defined; the next section discharges that assumption — Theorem 1.3 and Corollary 1.1 establish existence and uniqueness without using this equation, so the reasoning is not circular. An optimal trajectory’s tail is itself optimal from the state it reaches. Fix . Any policy chooses a first action (or distribution over them) and then continues; its value cannot exceed taking the best first action and continuing optimally, which is exactly — so is at most the right-hand side. Conversely, the policy that takes the maximizing and then follows an optimal policy achieves that value, so is at least the right-hand side. Equality gives the optimality equation; the two bounds coincide exactly when the policy is greedy for .
The over actions makes this equation nonlinear — there is no matrix inverse to solve it. That nonlinearity is the entire reason we iterate rather than solve. Bertsekas Bertsekas (2017) develops the resulting theory abstractly as fixed-point iteration of monotone contraction operators; we specialize it to finite MDPs.
The Bellman optimality operator is
Theorem 1.2 says is a fixed point: .
The contraction that makes it all work
Both operators share one property, and it is the technical heart of the chapter. Recall a map is a -contraction in a norm if for all .
For any ,
Both operators are -contractions on .
We prove it for ; the case is Exercise 1 (it is easier — no ). The bound takes four short steps, each labelled with the rule it uses. Fix a state and write , so . The one inequality we need is that the is nonexpansive: . Then
The bound is uniform in , so taking the max over on the left gives .
The discount is doing all the work: it is literally the contraction modulus. With the bound is vacuous and the fixed-point theory needs extra structure (proper policies, average cost) — the subject of later asides.
Because is complete and both operators are -contractions, the Banach fixed-point theorem gives:
- has a unique fixed point, necessarily ; and has a unique fixed point, necessarily . In particular exists and is unique, and an optimal stationary policy exists (any greedy policy for — the policy-improvement theorem below confirms such a policy attains ).
- The iterates converge to from any start , geometrically:
This corollary is the payoff. It converts an existence question (“is there a best policy?”) into a convergent algorithm (“iterate the operator”), and it tells us the error shrinks by a factor every sweep.
Value iteration
Value iteration is now nothing more than iterate to its fixed point.
V ← 0 (any initial vector in ℝ^𝒮)
repeat:
V ← 𝒯* V # one sweep of the optimality operator
until ‖ΔV‖∞ < ε(1−γ)/γ # stopping rule, justified below
return V, and the greedy policy π(s) = argmax_a [ r(s,a) + γ Σ p(s'|s,a) V(s') ]Corollary 1.1 guarantees convergence. The stopping rule deserves a word: a small Bellman residual bounds the true error, because
This telescopes from the contraction — write and bound each term geometrically (Exercise 5). So stopping when
certifies
— a guarantee we can check at
runtime without knowing . The companion
experiments/python/week01/dp.py implements exactly this loop with the explicit
operator as a standalone function, as the roadmap’s Week-1 task asks.
Policy iteration
Value iteration improves the value every sweep and reads off a policy at the end. Policy iteration instead alternates two exact steps on the policy, and was Howard’s original 1960 algorithm Howard (1960) :
- Policy evaluation. Given , solve the linear system for (the affine fixed point of — Def. 1.4).
- Policy improvement. Set , greedy w.r.t. the freshly evaluated values.
Repeat until the policy stops changing. The step that makes this work is:
Let be greedy with respect to , so that for all . Then for all , with strict improvement in some state unless is already optimal.
Expand the greedy inequality and re-apply it along the trajectory:
If no state improves strictly, the greedy inequality holds with equality everywhere, which is the Bellman optimality equation — so is already optimal.
Because the MDP is finite there are finitely many deterministic policies, each iteration strictly improves until none does, so policy iteration terminates at an exact optimum in finitely many steps. Value iteration and policy iteration are the two poles of what Sutton & Barto Sutton & Barto (2018) call generalized policy iteration: any interleaving of “make the value consistent with the policy” and “make the policy greedy for the value” converges to the same fixed point. Week 2 studies what happens between the poles — asynchronous, Gauss–Seidel, and prioritized sweeps.
The dynamic-programming bridge
The roadmap’s Week-1 writing prompt is to place the Bellman equation beside its continuous cousin. They are the same principle of optimality at different limits. Discretize time and state and the cost-to-go obeys the discrete Bellman recursion above; take the limit of vanishing time-step on a continuous state and the same recursion becomes the Hamilton–Jacobi–Bellman equation. Control flips the convention from maximizing reward to minimizing a running cost , with cost-to-go ; the stationary discounted HJB equation is
whose term is the continuous-time echo of the discount that drove the contraction above (set for the undiscounted limit). Value iteration is the fixed-point solver for the discrete equation; the LQR Riccati recursion (Ch. 13) is the closed-form solver for the HJB equation when is linear and is quadratic. Holding this identity in view is the point of the whole curriculum: control theory and RL are two dialects for the same fixed point.
What’s next
- Week 2 opens up the iteration itself: asynchronous and Gauss–Seidel value iteration, prioritized sweeping, real-time DP, and residual scheduling — the practical face of “iterate the contraction.”
- Week 3 replaces the known model with sampled returns (Monte Carlo), the first step away from dynamic programming toward learning.
Exercises
-
(Prove) Show that the Bellman expectation operator is a -contraction in . (This is the no- case of Theorem 1.3.)
Solution
For any , since cancels. Taking absolute values and using the triangle inequality with , . Maximizing over gives the claim. (No -nonexpansiveness step is needed, because is affine.)
-
(Derive) State and prove the Bellman expectation equation for the action-value .
Solution
Conditioning on the first transition and then the next action,
The derivation is identical to Theorem 1.1 with the first action held fixed at and the recursion closing on via .
-
(Compute) Take the two-state MDP , actions , , with deterministic dynamics: in , stay () and switch (); in , stay () and switch (). Evaluate the always-stay policy by solving .
Solution
Under always-stay, and , so gives , i.e. . State self-loops collecting forever (); state self-loops collecting . This is the exact case the companion test asserts.
-
(Prove) Derive the geometric error bound of Corollary 1.1(2), , from the contraction property and .
Solution
by Theorem 1.3 and the fixed-point identity. Iterating the inequality times gives the bound.
-
(Implement) Add the certified stopping rule to value iteration: stop when and verify empirically that the returned satisfies on the two-state MDP (using the analytic ). Run against
experiments/python/week01/dp.py.Solution
The bound follows by writing and bounding each term by the contraction: , a geometric series summing to . The companion’s
value_iteration(..., tol=ε)implements this and its test asserts the resulting error is below . -
(Extend) Show the optimal value function is the solution of the linear program subject to for all .
Solution
Feasibility means pointwise; by monotonicity of this implies , so is the smallest feasible point and minimizing selects it. The constraints linearize the (one inequality per action), turning the nonlinear optimality equation into an LP — the basis of the dual/occupancy-measure view revisited with safe RL in Week 25.
Companion code
The Week-1 companion lives at experiments/python/week01/ (the repo’s
three-language convention). It is pure NumPy at the core — the algorithms and the
correctness test carry no environment dependency — with an optional Gymnasium
adapter for the canonical FrozenLake showcase.
dp.py— the Bellman optimality operator as an explicit function, plusvalue_iteration,policy_evaluation(exact linear solve),policy_improvement, andpolicy_iteration, all on a generic finite MDP(P, R, gamma).test_dp.py— mathematical-correctness tests: convergence to the analytic on the two-state MDP of Exercise 3, the contraction inequality of Theorem 1.3, the fixed-point identity, the geometric bound, and VI/PI agreement (FrozenLake checks run only whengymnasiumis installed).frozenlake.py— builds(P, R, gamma)fromgymnasium’sFrozenLake-v1and runs VI and PI as a worked showcase.
# core algorithms + correctness tests (no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week01/test_dp.py -q
# canonical FrozenLake showcase (optional extra: pip install "gymnasium")
PYTHONPATH=. python experiments/python/week01/frozenlake.pyAsynchronous and Prioritized Dynamic Programming
Keeping the gamma-contraction but varying the schedule: asynchronous and Gauss–Seidel value iteration, prioritized sweeping, and real-time DP. Why the order of backups is free — monotonicity plus a constant-shift identity — and how update order and residual size set the practical convergence rate.
Asynchronous and Prioritized Dynamic Programming
Where we are. Chapter 1 proved that value iteration and policy iteration both reach the optimal value function because the Bellman operators are -contractions. Both methods share one extravagance: every sweep backs up every state, in lockstep, whether or not that state’s value has stopped moving. This chapter keeps the contraction and varies only the schedule — which states we back up, in what order, and using whose values. The load-bearing claim is that the order is nearly free: as long as every state is updated infinitely often, asynchronous dynamic programming converges to the same fixed point , and ordering the updates well — Gauss–Seidel, prioritized sweeping, real-time DP — buys large savings without touching the convergence theory.
Generalized policy iteration: the space between the poles
Chapter 1 closed by naming value iteration and policy iteration the two poles of generalized policy iteration (GPI): VI applies one optimality backup everywhere and reads off a greedy policy at the end; PI evaluates a policy exactly (a linear solve) and then improves it greedily. The methods in between truncate the evaluation. Modified policy iteration Puterman (1994) runs sweeps of the expectation operator in place of the exact solve: recovers value iteration, recovers policy iteration, and intermediate trades evaluation cost against the number of outer improvements. Sutton & Barto Sutton & Barto (2018) frame the entire family as two interacting processes — make the value consistent with the policy, make the policy greedy for the value — that converge to the same fixed point regardless of how finely they are interleaved.
This chapter relaxes a different lockstep: not how much we evaluate between improvements, but which states we touch on each pass and in what order.
Asynchronous value iteration
Synchronous value iteration computes the whole vector from and only then overwrites — every state is backed up from the same old values. Asynchronous value iteration drops that barrier.
Asynchronous value iteration maintains a single value vector and repeats: select a state and overwrite
using the current entries of — including any updated earlier in the pass. States may be visited in any order, subject only to the fairness condition that every state is selected infinitely often. The special case that sweeps the states in a fixed order , each backup seeing the freshly written values of its predecessors, is Gauss–Seidel value iteration.
The synchronous operator of Chapter 1 reuses no in-pass information; Gauss–Seidel reuses all of it; general asynchronous iteration lives anywhere between. The question is whether dropping the barrier costs us the convergence guarantee. It does not, and the reason is two structural facts that cost one line each.
Why the order is free: monotonicity and the constant-shift identity
Let be either Bellman operator ( or ). For all and every constant , writing for the all-ones vector:
- Monotonicity. If componentwise, then .
- Constant-shift. .
Both read off the backup , of which and .
Monotonicity. If then because the transition weights are nonnegative; hence for every , and taking the (or the -average) over preserves the inequality.
Constant-shift. Since , replacing by adds exactly to every ; and (likewise for the average).
These two facts — and not the full contraction algebra — are what make asynchronous order irrelevant.
Run asynchronous value iteration (Def. 2.1) from any , updating every state infinitely often. Then . Moreover, grouping the schedule into rounds — a round ends once every state has been backed up at least once since the round began — the sup-norm error contracts by a factor per round:
Let , so the iterate starts inside the box . Suppose at some moment lies in this box. Back up any state . By monotonicity and then constant-shift (Prop. 2.1), using ,
So the updated entry lands in the smaller box (as ). Two consequences: the iterate never leaves the original -box, and every state, once backed up, sits in the -box. Crucially, later backups in the round still read values inside the original -box, so they too map into the -box. Hence after one full round . Applying the argument round by round gives after rounds; fairness guarantees infinitely many rounds, so .
Synchronous value iteration is the special case in which a round is a single simultaneous sweep, and the bound collapses to Chapter 1’s . The abstract version — monotone contraction operators converge under any fair asynchronous schedule — is the backbone of Bertsekas’s treatment of dynamic programming Bertsekas (2017) .
Gauss–Seidel sweeps and the numerical-analysis analogy
The names are borrowed deliberately. Solving a linear system by splitting and iterating, Jacobi updates every coordinate from the previous iterate (a synchronous sweep), while Gauss–Seidel updates coordinate using the already-updated coordinates — in place, no second buffer. Value iteration is the nonlinear analogue: synchronous VI is Jacobi, Gauss–Seidel VI is Gauss–Seidel. The in-place version typically converges in fewer sweeps because information propagates across the state space within a single pass rather than waiting a full sweep per hop, and it halves the memory (no separate buffer). Theorem 2.1 already covers it: a left-to-right sweep updates every state once, so it is exactly one round.
The order within a sweep is now a design lever. If states are numbered along the direction reward information flows — outward from a goal, say — a single Gauss–Seidel sweep can propagate values across the whole space, whereas the reverse order wastes most of the pass. This is the seed of prioritizing the order rather than fixing it.
The Bellman residual and residual scheduling
How do we know where values are still moving? The same quantity that certifies stopping. Recall from Chapter 1 the local Bellman residual at a state, the amount one more backup would change it,
and that the global residual controls the true error through . A uniform sweep spends equal effort on states with (already converged) and on states with large (still far off). Residual scheduling is the obvious correction: back up states in decreasing order of , and skip states whose residual sits below a tolerance . Asynchronous convergence (Thm. 2.1) licenses any such order as long as no state is starved.
Prioritized sweeping
Prioritized sweeping Moore & Atkeson (1993) makes residual scheduling precise with a priority queue, and adds the key idea that a backup only changes a state’s predecessors, so only their priorities need refreshing.
initialize V ← 0; priority queue PQ keyed by Bellman residual
seed PQ with every state s at priority |(𝒯* V)(s) − V(s)|
repeat:
s ← PQ.pop_max() # largest-residual state
V(s) ← (𝒯* V)(s) # one optimality backup
for each (s̄, a) with p(s | s̄, a) > 0: # predecessors that feed s
e ← |(𝒯* V)(s̄) − V(s̄)| # their refreshed residual
if e > θ: PQ.push(s̄, priority = e)
until PQ empty # every residual below θOn a sparse-reward problem the queue concentrates work near the frontier where values are actually changing, leaving the converged interior untouched; Moore and Atkeson report order-of-magnitude reductions in backups to reach a target accuracy on large MDPs. The method is exact-model dynamic programming — it needs to form both the backup and the predecessor sets — but it is the direct ancestor of the sampled prioritized-replay schemes that return in Week 6.
Real-time dynamic programming
Prioritized sweeping orders updates by residual; real-time dynamic programming (RTDP) orders them by reachability Barto et al. (1995) . Instead of enumerating states, RTDP backs up only the states it actually visits while acting greedily, interleaving computation with control.
repeat for each trial:
s ← start state
while s is not terminal:
V(s) ← (𝒯* V)(s) # back up the current state
a ← greedy action at s w.r.t. V
s ← sample s' ∼ p(· | s, a) # follow the greedy trajectoryBecause backups concentrate on the states reachable under good policies, RTDP can solve problems whose full state space is far too large to sweep, converging on the relevant subset without ever touching the rest. It is also the conceptual hinge to model-free learning: replace the expectation in the backup with the single sampled successor, and the deterministic backup becomes a stochastic one — RTDP’s Monte-Carlo cousin is Q-learning, which Weeks 3–4 build from exactly this move.
Counting the work: iterations and samples
How many backups does the discount cost us? For synchronous value iteration the geometric bound answers it directly.
Starting from , synchronous value iteration reaches after
sweeps, where .
With , Chapter 1’s Corollary 1.1 gives , using the return bound . Requiring the right side and taking logs gives the displayed . The order form uses for , so .
The count is only logarithmic in the accuracy but linear in the effective horizon — push toward and the work grows without bound. Tseng Tseng (1990) made this precise, showing stationary discounted MDPs are solved in time proportional to of the horizon. The same governs the sample cost once the model is unknown: given only a generative model (a sampler for ), estimating an -optimal value needs samples, a bound matched from both sides by Azar et al. Azar et al. (2013) and achieved in near-optimal time by the variance-reduced value iteration of Sidford et al. Sidford et al. (2018) . That cubic blow-up in the horizon is precisely the pressure that drives the curriculum out of the exact-model regime and into sampling (Week 3) and function approximation (Week 5).
The dynamic-programming bridge
Asynchronous DP is where the numerical-analysis reading of value iteration becomes literal. A value function is a point in ; the Bellman operator is a nonlinear map whose fixed point we chase; and the Jacobi / Gauss–Seidel / residual-ordered hierarchy is the same one used to solve large sparse linear systems, transplanted to a contraction that happens to involve a . Two threads carry forward:
- To online control (MPC, Week 15). RTDP’s instinct — compute only over the states you will actually visit, refreshing as you go — is the tabular shadow of model predictive control, which re-solves a short-horizon optimal-control problem from the current state at every step instead of storing everywhere.
- To model-free RL (Weeks 3–6). Replace the model expectation in a backup with a sampled successor and asynchronous DP becomes temporal-difference learning; prioritized sweeping becomes prioritized experience replay. The schedule ideas of this chapter reappear, now applied to which transitions to learn from.
What’s next
- Week 3 removes the known model entirely: values are estimated from sampled returns (Monte Carlo), trading the model expectation for an empirical average and introducing the bias–variance questions that dominate the rest of Part I.
- Week 4 fuses the two views — bootstrapping like DP, sampling like Monte Carlo — into temporal-difference learning, the stochastic-approximation form of the asynchronous backup above.
Exercises
-
(Prove) Show that the Bellman optimality operator satisfies the constant-shift identity for every (Prop. 2.1(2)), and explain where the proof of Theorem 2.1 uses it.
Solution
For each , since the transition row sums to , so every rises by ; the per-state then rises by . Theorem 2.1 uses it to evaluate , which shrinks the bounding box by a factor each round.
-
(Derive) Argue that one full Gauss–Seidel sweep is one “round” in the sense of Theorem 2.1, and conclude that Gauss–Seidel value iteration converges at least as fast (per sweep) as synchronous value iteration.
Solution
A left-to-right sweep updates each state exactly once, so by the end every state has been backed up since the sweep began — a round — and Theorem 2.1 gives . Synchronous VI achieves the same per-sweep factor but reads only stale values; Gauss–Seidel additionally uses freshly updated predecessors within the sweep, so its actual contraction per sweep is no worse and usually strictly better.
-
(Compute) A backup at state changes the residual of which other states? Give the set in terms of , and explain why prioritized sweeping only re-queues those.
Solution
Only the predecessors : a state ‘s backup depends on only if some action from can reach . Every other state’s residual is unchanged by overwriting , so re-evaluating it would be wasted work — hence the predecessor loop in the prioritized-sweeping inner step.
-
(Implement) In the companion, run synchronous VI, Gauss–Seidel VI, and prioritized sweeping on the stochastic gridworld and verify (i) all three reach the policy-iteration value , and (ii) to reach a fixed target accuracy — set the prioritized-sweeping threshold — prioritized sweeping spends fewer state-backups than the synchronous sweep count .
Solution
See
experiments/python/week02/test_async_dp.py: it asserts each method matchesdp.policy_iteration, and that at the prioritized-sweeping backup count is below the synchronous total. The win is in reaching useful accuracy fast — the queue concentrates on high-residual states — and it widens with ; the edge narrows as approaches machine precision, where residuals near the fixed point thrash the queue. -
(Extend) Perturb the gridworld’s transition model (raise the slip probability) and measure how the optimal policy and change. Relate the sensitivity to the factor in Proposition 2.2.
Solution
A model error of size in perturbs the fixed point by (a simulation-lemma bound — a perturbation bound on the DP fixed point): the same effective horizon that sets the iteration count also amplifies model error, which is the quantitative reason model misspecification hurts more as . The companion’s
--slipsweep exhibits the effect.
Companion code
The Week-2 companion lives at experiments/python/week02/ and reuses the Week-1
primitives — it imports dp.py for action_values, bellman_optimality_operator,
value_iteration, and policy_iteration rather than reimplementing them, so the
asynchronous methods are checked against the same reference fixed point.
gridworld.py— builds a parametric stochastic gridworld as a generic(P, R, gamma)MDP in thedp.pyrepresentation: a goal cell, a per-step cost, and a slip probability that randomizes the intended move. Pure NumPy.async_dp.py— Gauss–Seidel (in-place) value iteration and model-based prioritized sweeping with an explicit predecessor index and a backup counter, both built on thedp.pyoperators.test_async_dp.py— mathematical-correctness tests: Gauss–Seidel and prioritized sweeping converge to the same asvalue_iterationandpolicy_iteration(from arbitrary starts); the constant-shift and monotonicity properties of Proposition 2.1 hold numerically; and prioritized sweeping uses fewer backups than a synchronous sweep schedule to reach a target accuracy on a sparse-reward grid.
# core algorithms + correctness tests (pure NumPy, no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week02/test_async_dp.py -q
# worked comparison + optional value/residual heatmaps (saved locally, not committed)
PYTHONPATH=. python experiments/python/week02/async_dp.py --plotMonte Carlo Methods
Estimating value from sampled returns when the model is unknown: first-visit Monte Carlo prediction, Monte Carlo control by generalized policy iteration, and off-policy learning by importance sampling. Monte Carlo estimation as quadrature — unbiased, model-free, and high-variance, with the fragility of off-policy correction.
Monte Carlo Methods
Where we are. Chapters 1 and 2 assumed the model was known and computed value functions by iterating the Bellman operator. This chapter takes the first step of reinforcement learning proper: the model is unknown, and value is estimated from sampled experience. The load-bearing shift is one substitution — replace the model expectation inside the value definition with an empirical average over complete sampled returns. The estimate is unbiased and needs no model, but it pays for that in variance and requires episodic tasks that terminate.
From a known model to sampled returns
The definition of the state-value function (Chapter 1) is an expectation over trajectories,
where an episode runs from to a terminal time . Dynamic programming never sampled ; it used the model to turn this expectation into the Bellman recursion. Monte Carlo does the opposite: it leaves the expectation alone and estimates it the way one estimates any expectation without a closed form — draw samples and average.
That reframing — value estimation as quadrature — sets the terms for the whole chapter. The sample mean of returns is unbiased regardless of dimension, and its error falls like in the number of episodes ; the variance of the return is the price of having no model. Two structural requirements follow: episodes must terminate (an infinite return has no sample), and estimating requires acting under — or correcting for the fact that we did not, which is the off-policy problem below.
First-visit Monte Carlo prediction
To estimate , generate episodes under and, for each state, average the returns that followed visits to it. The first-visit variant averages only the return following the first time each state is reached in an episode, which gives one independent draw per episode (every-visit MC reuses correlated within-episode returns).
Run episodes under . For state , let index the episodes in which is visited, and for episode let be the return from the first visit to . The first-visit Monte Carlo estimate is the sample mean
Each first-visit return is an independent sample of under . Hence is unbiased, , and by the strong law of large numbers almost surely as .
Fix . In each episode the first visit to occurs at some time , and the return from that point, , is by construction a draw of the random variable conditioned on and on following thereafter — so its expectation is exactly by the definition above. Different episodes are generated independently, and using only the first visit means each episode contributes one draw that does not depend on the others (every-visit sampling would reuse correlated within-episode returns). The are thus i.i.d. with mean ; a sample mean of i.i.d. draws is unbiased, and the strong law gives almost-sure convergence.
The estimator carries no bias and no model — it never references , only realized returns. Its weakness is variance: a single return aggregates all the randomness of a whole trajectory, so can be large and convergence is only . Sutton & Barto Sutton & Barto (2018) treat first- and every-visit MC and the bias each incurs; every-visit MC is biased in finite samples (its within-episode returns overlap, so the averaged samples are correlated, though the bias vanishes as ) but also consistent, and is often simpler to implement.
Monte Carlo control
Prediction estimates ; control seeks . Monte Carlo control is generalized policy iteration (Chapter 2) with the evaluation step done by sampling: estimate the action-value from returns, then improve the policy greedily, . The catch is exploration. With no model, an action that is never tried has no return to average, so its value is unknown and greedy improvement can lock onto a wrong choice. Two standard fixes guarantee every action keeps being sampled:
- Exploring starts — begin episodes from a random state–action pair, so every seeds infinitely many returns.
- -soft policies — keep the behaviour policy stochastic ( for all ), so no action is ever starved; improvement then converges to the best -soft policy rather than the unconstrained optimum.
Either way the GPI logic of Chapter 1 carries over — evaluate, improve, repeat — with the policy-improvement theorem still guaranteeing monotone improvement at each step that uses an accurate estimate. The convergence of exploring-starts MC control is taken as a working assumption here (it is not fully settled in general); Sutton & Barto Sutton & Barto (2018) discuss the subtlety.
Off-policy prediction and importance sampling
Often we must estimate for a target policy while the data was generated by a different behaviour policy — for instance to evaluate a greedy policy from exploratory data. Naively averaging returns from estimates , not . Importance sampling corrects the distribution mismatch by reweighting each return.
For a trajectory from to termination , the importance-sampling ratio is the likelihood ratio of the action choices (the dynamics cancel, being shared),
Over the first-visit returns with ratios , the ordinary and weighted importance-sampling estimators of are
Assuming coverage ( whenever ), ordinary importance sampling is unbiased, . Weighted importance sampling is biased in finite samples but consistent (), and typically has far lower variance.
The probability of a trajectory’s action sequence under equals times its probability under , because the environment factors appear identically in both and cancel — only the policy factors survive in the ratio. This is a change of measure: for any function of the trajectory, . Taking gives , so the ordinary estimator (a sample mean of ) is unbiased. The weighted estimator divides by rather than the count; as a ratio of two correlated sample means it is biased at finite , but both means converge ( and ), so the ratio converges to .
The two estimators sit at opposite ends of the bias–variance axis, and the variance end is where off-policy Monte Carlo becomes fragile. The ratio is a product over the episode; if and differ enough — or the horizon is long — the product swings across orders of magnitude, and the variance of ordinary IS can be unbounded: a single rare trajectory with a huge ratio dominates the average. Weighted IS caps this — its estimate can never exceed the largest observed return — trading a vanishing bias for a decisive variance reduction, which is why it is the practical default. Both degrade as the horizon grows and more ratio factors multiply in; this fragility is a major reason the field leans on the lower-variance, bootstrapped methods of Week 4.
The dynamic-programming bridge
Monte Carlo and dynamic programming estimate the same object from opposite information. DP needs the model and bootstraps — each value is written in terms of other current estimates — giving low variance but model dependence and bias while the estimates are wrong. MC needs only the ability to sample episodes and never bootstraps — each value is an average of full returns — giving no model dependence and no bias but high variance, and only for terminating tasks. Plotted on two axes, bootstrapping and sampling, DP samples nothing and bootstraps fully; MC samples fully and bootstraps not at all. Week 4’s temporal-difference learning is the missing corner: sample like MC, bootstrap like DP, and inherit a blend of their bias and variance.
What’s next
- Week 4 introduces temporal-difference learning: replace the full sampled return with the one-step bootstrap , fusing Monte Carlo sampling with the dynamic-programming backup and removing the need to wait for an episode to terminate.
- Week 5 confronts what happens when is a parametric approximation rather than a table, where bootstrapping and off-policy data interact dangerously.
Exercises
-
(Prove) Show the first-visit Monte Carlo estimator is unbiased for for every fixed sample size, citing where independence across episodes is used (Prop. 3.1).
Solution
Each first-visit return has by the definition of the value as the expected return from under . The estimator is the mean of such draws, so by linearity — unbiased at any . Independence (one draw per episode, first visit only) is not needed for unbiasedness but is what makes the variance and licenses the strong law for consistency.
-
(Derive) Starting from the trajectory likelihood under and , derive the importance-sampling ratio and show (Prop. 3.2).
Solution
The probability of given factors as . Dividing the -likelihood by the -likelihood, every factor cancels, leaving . Then .
-
(Compute) Target is greedy (prob. 1 on action ); behaviour is uniform over two actions. For an episode of length 3 that happens to take at every step, compute . What is if any step takes the non-target action?
Solution
Each on-target step contributes , so . If any step takes the non-target action, there, so — that trajectory contributes nothing, the discrete face of the variance problem (a few high-ratio trajectories carry the whole estimate).
-
(Implement) On the companion’s random-walk MDP, verify first-visit MC converges to the analytic from
dp.policy_evaluation, and that ordinary IS is unbiased while weighted IS has lower variance across seeds.Solution
See
experiments/python/week03/test_mc.py: it computes exactly with the Week-1 linear solve, then asserts first-visit MC matches it within a sampling tolerance, the ordinary-IS mean across many seeds is unbiased, and — when the behaviour policy under-samples the reward path (the heavy-tailed regime; under a mild mismatch ordinary IS is already low-variance) — the weighted-IS empirical variance is below the ordinary-IS variance. -
(Extend) Make the behaviour policy progressively worse (further from ) and measure how ordinary- and weighted-IS variance grow. Relate the blow-up to the product structure of .
Solution
As diverges from , individual step ratios stray from and their product’s variance compounds geometrically in the horizon; ordinary-IS variance grows fastest (it can be unbounded), weighted-IS more slowly (bounded by the largest return). The companion’s
--mismatchsweep exhibits the monotone growth.
Companion code
The Week-3 companion lives at experiments/python/week03/ and reuses the Week-1
linear solve (dp.policy_evaluation) as the exact oracle against which the sampled
estimates are checked — the core suite has no environment dependency.
randomwalk.py— builds a small episodic random-walk MDP (terminal states at both ends) as a generic(P, R)array pair, so is available in closed form fromdp.policy_evaluation.mc.py— episode sampling from a generic(P, R, policy), first-visit MC prediction, and off-policy prediction with both ordinary and weighted importance sampling. Pure NumPy.test_mc.py— statistical-correctness tests: first-visit MC converges to the analytic within a sampling tolerance; ordinary IS is unbiased across seeds; weighted IS has strictly lower empirical variance.blackjack.py— the canonical Sutton & Barto Monte-Carlo showcase: MC control on Gymnasium’sBlackjack-v1(optional extra; skipped when Gymnasium is absent).
# core algorithms + correctness tests (pure NumPy, no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week03/test_mc.py -q
# canonical Blackjack MC-control showcase (optional: pip install "gymnasium")
PYTHONPATH=. python experiments/python/week03/blackjack.pyTemporal-Difference Learning: TD(0), SARSA, and Q-Learning
Bootstrapping from sampled transitions: the TD(0) prediction update as a stochastic Euler step toward the Bellman fixed point, SARSA as on-policy control, and Q-learning as off-policy control. Where temporal-difference learning sits between Monte Carlo and dynamic programming, and what the SARSA/Q-learning split reveals on the cliff.
Temporal-Difference Learning: TD(0), SARSA, and Q-Learning
Where we are. Monte Carlo (Chapter 3) waited for a full episode to terminate, then averaged the realized return — unbiased, but high-variance and episodic-only. Dynamic programming (Chapters 1–2) never sampled at all; it bootstrapped each value from other current estimates through the model. Temporal-difference learning is the missing synthesis: sample one transition like Monte Carlo, and bootstrap from the current estimate like dynamic programming. The result learns online, from a single step, with no model and no wait for the episode to end. Its load-bearing object is the TD error — a one-sample estimate of the Bellman residual.
The TD(0) update
Given a single transition generated under , TD(0) nudges the value of the visited state toward a bootstrapped target:
with step size . Compare the three targets we have now for the same quantity : Monte Carlo uses the full sampled return (no bootstrap, needs the episode to end); dynamic programming uses the model expectation (full bootstrap, needs the model); TD(0) uses — one sampled successor plus a bootstrap off the current estimate. It updates every step, online, and never references .
TD(0) as a stochastic Euler step
Why should nudging toward a bootstrapped (hence biased, while ) target converge to the right answer? Because in expectation the nudge is a Bellman-operator step.
For any value estimate and any state , the expected TD error under is the Bellman expectation residual,
Hence the expected TD(0) update moves a fraction of the way toward .
Condition on and average over the action and transition drawn under :
So .
Read the deterministic part as a forward-Euler step on the ODE , whose unique equilibrium is the fixed point — that is, . TD(0) follows this flow with stochastic targets, so it is a Robbins–Monro stochastic-approximation scheme: under the step-size conditions , and every state visited infinitely often, Sutton & Barto (2018) Bertsekas (2017) . The contraction of Chapter 1 supplies the stability the ODE needs; sampling supplies the variance that the diminishing averages away.
SARSA: on-policy control
Prediction estimates ; control needs action-values. SARSA forms the same TD error on from the quintuple — its namesake — where is the action the agent actually takes next under its (typically -greedy) policy:
Because the bootstrap uses the value of the sampled next action, SARSA is on-policy: it evaluates and improves the very policy it follows. Interleaving this evaluation with -greedy improvement is generalized policy iteration (Chapter 1) driven by sampled errors; under GLIE (greedy in the limit with infinite exploration — slowly) it converges to .
Q-learning: off-policy control
Q-learning Watkins & Dayan (1992) changes one symbol — the next action is replaced by the greedy one:
That makes the target the sampled optimality backup, so Q-learning learns directly while behaving by any sufficiently exploratory policy — it is off-policy. Watkins and Dayan proved with probability one under the Robbins–Monro step sizes and infinite visits to every state–action pair. The contrast with SARSA is exactly the contrast between the two operators of Chapter 1, now on action-values.
With the action-value operators and , the expected one-step targets are
So SARSA’s fixed point is (for the policy it follows) and Q-learning’s is .
Average each target over drawn from . SARSA additionally averages , producing inside the bracket — exactly . Q-learning takes deterministically, producing . A stochastic-approximation step toward a -contraction’s value converges to its unique fixed point (Prop. 4.1’s argument, now for the action-value operators): for , for .
On-policy vs off-policy: the cliff
The split is not academic. On the cliff-walking gridworld — a corridor whose bottom edge is a cliff that costs a large penalty and resets the agent — an optimal agent walks right along the cliff’s lip, the shortest path. Q-learning, estimating , learns exactly that risky-optimal route. SARSA, estimating for the -greedy policy it actually follows, accounts for the fact that exploration will occasionally step it off the cliff, so it prefers a safer path one row up. Both are correct about different questions — and at a fixed , the start-state value Q-learning reports is the higher (optimal) one, while SARSA’s is lower because it embeds the cost of exploration. The companion measures exactly this gap.
n-step TD and the bias–variance dial
TD(0) and Monte Carlo are the endpoints of one family. The -step return bootstraps after sampled rewards; is TD(0), is Monte Carlo. Larger samples more (higher variance, less bootstrap bias); smaller bootstraps more (lower variance, more bias while is wrong). Intermediate — and its geometric average TD() — usually beats both endpoints, the bias–variance dial made adjustable.
The dynamic-programming bridge
Temporal-difference learning closes a loop opened in Chapter 2. Real-time DP applied asynchronous Bellman backups along trajectories, but using the model expectation . Replace that expectation with a single sampled successor and the deterministic backup becomes the stochastic TD update — RTDP’s “Monte-Carlo cousin,” promised in Chapter 2, is precisely Q-learning. The three methods now form a clean table on two axes:
- Dynamic programming — bootstrap, no sample (model expectation, full sweep).
- Monte Carlo — sample, no bootstrap (full return, episode end).
- Temporal difference — sample and bootstrap (one transition, online).
All three chase the same fixed point of the same -contraction; they differ only in how much they sample and how much they bootstrap.
What’s next
- Week 5 replaces the value table with a parametric approximator . Bootstrapping (this chapter), off-policy data (Q-learning), and function approximation together form the deadly triad — the first place the clean contraction story breaks, because approximation moves the fixed point itself.
Exercises
-
(Derive) Show for any , and conclude TD(0) is a stochastic step toward (Prop. 4.1).
Solution
. The expected update is therefore , a damped step of the -contraction whose fixed point is .
-
(Prove) Show the expected Q-learning target is and the expected SARSA target is , hence their fixed points are and (Prop. 4.2).
Solution
Averaging over : Q-learning’s gives . SARSA additionally averages , giving . The fixed points follow from the contraction of each operator.
-
(Compute) With , , current , observed , : compute and the updated .
Solution
; . The same numbers drive a SARSA or Q-learning update with in place of (the sampled-action value for SARSA, the max for Q-learning).
-
(Implement) In the companion, verify TD(0) converges to the analytic on the random walk; that Q-learning (GLIE) recovers the optimal cliff-edge policy while SARSA settles on the safer, slightly longer route; and that at a fixed Q-learning’s start-state value is at least SARSA’s.
Solution
See
experiments/python/week04/test_td.py: TD(0) matchesdp.policy_evaluationwithin a sampling tolerance; Q-learning’s greedy policy attains the optimal start-state value fromdp.value_iterationwhile SARSA’s greedy is a sensible but suboptimal goal-reaching route (the safe path), so the off-policy greedy value is the on-policy one; and the fixed- start-state estimate of Q-learning is SARSA’s — the optimism/realism gap. -
(Extend) Sweep in -step TD on the random walk and reproduce the characteristic U-shaped error-vs- curve (an intermediate beats both TD(0) and Monte Carlo).
Solution
Bootstrapping bias falls with while sampling variance rises; the sum is minimized at intermediate . The qualitative U-curve over (for a fixed ) is the standard Sutton & Barto result; the companion’s
--nstepsweep reproduces it.
Companion code
The Week-4 companion lives at experiments/python/week04/ and reuses earlier
weeks: the random walk from Week 3 (randomwalk.py) for prediction, and the Week-1
dp solvers as the exact oracle for both prediction and control.
cliffwalk.py— a self-contained cliff-walking MDP (the Sutton & Barto Example 6.6 layout: a cliff row that penalizes and resets) as a generic(P, R)array pair, so and the optimal policy come fromdp.value_iteration.td.py— the transition sampler plustd0_prediction,sarsa, andq_learning, all operating on a generic(P, R, terminals), with optional GLIE schedules (visit-count step sizes, decaying ). Pure NumPy.test_td.py— mathematical-correctness tests: TD(0) converges to the analytic ; under GLIE Q-learning recovers the optimal start-state value while SARSA learns the safer, slightly longer route; and Q-learning’s fixed- start value is at least SARSA’s (the cliff’s on-/off-policy gap).
# core algorithms + correctness tests (pure NumPy, no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week04/test_td.py -q
# worked SARSA-vs-Q-learning comparison on the cliff (prints both learned paths)
PYTHONPATH=. python experiments/python/week04/cliffwalk.pyFunction Approximation and the Deadly Triad
Replacing the value table with a parametric approximator: linear value functions, semi-gradient TD, and the projected Bellman operator. Why on-policy semi-gradient TD converges to a bounded-error fixed point, and why function approximation, bootstrapping, and off-policy training together can diverge — the deadly triad, witnessed by Baird's counterexample.
Function Approximation and the Deadly Triad
Where we are. Every method so far stored one number per state in a table. That ends the moment the state space is large or continuous: we must approximate the value function with a parametric model and let it generalize across states. This chapter is the first where the clean contraction story of Chapters 1–4 breaks. Two results frame it. On-policy, semi-gradient TD still converges — but to a projected fixed point whose error is the representation’s projection error, amplified by : approximation changes the fixed point itself. Off-policy, the same update can diverge. The combination that breaks is named the deadly triad — function approximation, bootstrapping, and off-policy training — and Baird’s counterexample is its sharpest witness.
Linear approximation and semi-gradient TD
Replace the table with a parametric . We focus on the linear case, where a feature map () gives
The representable value functions form a -dimensional subspace of , where stacks the feature rows. Learning now adjusts , and a value learned at one state moves the values of all states sharing features — generalization, the whole point.
Given a transition , semi-gradient TD(0) updates
It is called semi-gradient because it treats the bootstrap target as fixed — it does not differentiate the target with respect to , so the update is not the true gradient of any fixed objective.
That last point is the crux of the chapter. A true-gradient method on a fixed loss cannot diverge to infinity; semi-gradient TD can, because the “target” it descends toward moves with .
The projected Bellman operator
Where does semi-gradient TD converge, when it does? Not to — that generally leaves the representable subspace and is not expressible as any . The update implicitly projects it back.
Let be a distribution over states and the weighted inner product, with norm . The projection maps a value function to the nearest representable one, . The TD fixed point is the satisfying
the fixed point of the composed projected Bellman operator .
Semi-gradient TD is a stochastic-approximation scheme (Chapter 4) for this fixed point: in expectation, under the state-visitation distribution its update drives toward . Whether that iteration converges hinges entirely on whether is a contraction — which depends on .
When it works: on-policy convergence
Let be the on-policy stationary distribution of (so ). Then is a -contraction in , and is nonexpansive in , so is a -contraction with a unique fixed point . Its error is the projection error, amplified by the horizon:
Two facts compose. (i) Under the stationary , the transition operator is nonexpansive in :
Since , this gives . (ii) is an orthogonal projection in , hence nonexpansive. So is a -contraction and has a unique fixed point (Banach, Ch. 1). For the bound, since we have , so
With the triangle inequality , substitute and solve to get the stated bound.
Two readings. First, convergence is conditional: it rests on being the on-policy distribution, the one fact that makes nonexpansive. Second, the fixed point moved: even at convergence the error is the projection error — what the feature space cannot represent — blown up by . With a table the projection error is zero and we recover exactly; with a poor feature space the fixed point can be far from . Tsitsiklis and Van Roy Tsitsiklis & Van Roy (1997) established exactly this convergence and bound for on-policy linear TD.
The deadly triad
Proposition 5.1 needed all three of its ingredients to be benign. Drop the on-policy assumption and the guarantee collapses. The instability requires the conjunction of three elements, each harmless alone — the deadly triad Sutton & Barto (2018) :
- Function approximation — a value model with fewer parameters than states.
- Bootstrapping — TD/DP targets that reuse current estimates (vs. Monte Carlo’s full returns).
- Off-policy training — updating from a distribution other than the policy’s own.
Any two are safe: tabular off-policy bootstrapping is Q-learning (Chapter 4, convergent); on-policy bootstrapping with approximation is Proposition 5.1; Monte Carlo with approximation and off-policy data is a genuine gradient method and is stable. All three together can make — now with the wrong (off-policy) distribution — an expansion, and the parameters diverge to infinity. Baird Baird (1995) built the canonical witness.
Seven states, a linear feature map of dimension eight, and zero reward everywhere — so is trivially representable (). The target policy always takes the “solid” action (to the seventh state); the behaviour policy explores all states (off-policy). Off-policy semi-gradient TD with uniform state weighting applies a linear update whose matrix has an eigenvalue with positive real part. The weights diverge geometrically even though a perfect, zero-error solution sits at the origin.
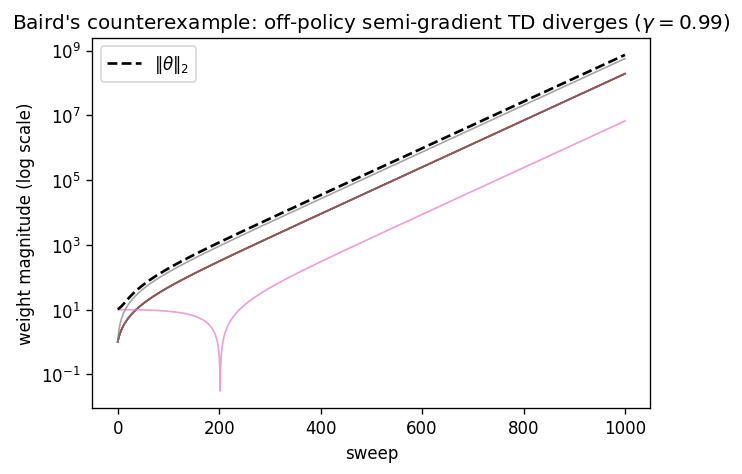
The lesson is not that approximation is hopeless but that the interaction is what bites: the projected operator’s contraction was an on-policy privilege, and off-policy data revokes it. The next chapter’s engineering — target networks and replay — exists precisely to tame this instability well enough to train deep off-policy value functions in practice.
Beyond semi-gradient: LSTD and true-gradient methods
Two routes around the difficulty are worth naming. Least-squares TD (LSTD) solves the linear TD fixed-point equations directly: accumulate and , then set — no step size, far more sample-efficient per datum, converging to the same on-policy fixed point as Proposition 5.1. Gradient-TD methods (GTD, TDC) instead descend a true objective (the projected Bellman error), restoring convergence even off-policy at the cost of a second set of weights. Both are the subject of the roadmap’s extension; LSTD appears in the companion.
The dynamic-programming bridge
Function approximation is the first crack in the contraction spine. Chapters 1–4 chased the unique fixed point of a -contraction; here the object becomes , and its fixed point both moves (by the projection error) and, off-policy, may not exist as a stable limit at all. Two bridges forward:
- To control (LQR, Ch. 13). The linear-quadratic regulator is the lucky case where the optimal value is exactly quadratic — representable with zero projection error — so the approximation never bites and the Riccati recursion converges cleanly. Most of control’s tractable cases are exactly this: a function class the true value lives inside.
- To deep RL (Week 6). DQN keeps bootstrapping, off-policy data, and a (nonlinear) approximator — the full triad — and survives by engineering the instability down: a slowly-updated target network freezes the bootstrap target, and experience replay decorrelates and re-weights the update distribution toward something tamer.
What’s next
- Week 6 builds DQN: the replay buffer and target network as direct countermeasures to the deadly triad, scaling approximate value learning to pixels.
Exercises
-
(Derive) Write the semi-gradient TD(0) update for linear and show it is not the gradient of . Identify the missing term.
Solution
. Semi-gradient TD uses (ascending ), dropping the term from differentiating the target. The dropped term is exactly what would make it a true gradient — and what, when present (residual-gradient methods), changes the fixed point and the stability.
-
(Prove) Show is a -contraction in when is the on-policy distribution, and derive the projection-error bound (Prop. 5.1).
Solution
is a -contraction in because is nonexpansive under the stationary (Jensen + ); is nonexpansive as an orthogonal projection; the composition is a -contraction. The bound follows from and the triangle inequality, as in the proof above.
-
(Compute) In Baird’s setup the update is . What property of (or of ) causes divergence, and why does a small not prevent it?
Solution
Divergence occurs iff has spectral radius , i.e. has an eigenvalue with positive real part (for small , exactly then). Shrinking only slows the geometric blow-up; it cannot flip the sign of the unstable eigenvalue. The companion computes ‘s spectrum.
-
(Implement) Verify on the companion that on-policy semi-gradient TD converges to (near) on the random walk, while off-policy semi-gradient TD on Baird’s counterexample diverges (the committed figure).
Solution
See
experiments/python/week05/test_fa.py: on-policy semi-gradient TD with tabular-complete features matchesdp.policy_evaluationwithin a sampling tolerance and keeps bounded weights; Baird’s off-policy update grows the weight norm without bound (the divergence the figure plots). -
(Extend) Implement LSTD and confirm it recovers the same on-policy fixed point as semi-gradient TD (and exactly when the features are tabular-complete).
Solution
LSTD solves with , ; its solution is the TD fixed point. With tabular-complete features the projection error is zero and reproduces , which the companion’s
lstdasserts against the Week-1 linear solve.
Companion code
The Week-5 companion lives at experiments/python/week05/ and reuses the Week-3
random walk and the Week-1 dp.policy_evaluation oracle. It is the chapter’s two
poles side by side: a convergent on-policy method and a divergent off-policy one. (The
roadmap suggests tile coding on MountainCar-v0; the random walk is used here because it
has a closed-form to test against — MountainCar tile-coding is a
natural deferred showcase that lacks an exact oracle.)
fa.py— linearsemi_gradient_td(constant step size with Polyak–Ruppert averaging) andlstdfor a generic(P, R, policy)with an arbitrary feature matrix . Pure NumPy.baird.py— Baird’s seven-state counterexample: builds the feature matrix and the off-policy expected-update matrix , iterates to divergence, and (with--plot) renders the committed divergence figure.test_fa.py— mathematical-correctness tests: on-policy semi-gradient TD converges to the analytic (and stays bounded); LSTD recovers with tabular-complete features; and Baird’s off-policy update diverges (the weight norm grows without bound while has an unstable eigenvalue).
# core algorithms + correctness tests (pure NumPy, no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week05/test_fa.py -q
# regenerate the committed Baird divergence figure
PYTHONPATH=. python experiments/python/week05/baird.py --plotThe DQN Family
Making approximate Q-learning stable enough for pixels: experience replay and target networks as direct countermeasures to the deadly triad, the overestimation bias that motivates Double DQN, and the dueling, prioritized, and Rainbow refinements. The engineering that scaled value-based RL to Atari.
The DQN Family
Where we are. Chapter 4 gave us Q-learning; Chapter 5 warned that combining bootstrapping, off-policy data, and function approximation — the deadly triad — can diverge. The deep Q-network is that exact combination (Q-learning, off-policy, with a neural-network approximator), and naively it does diverge. What made it work on Atari from pixels — first as a 2013 workshop result Mnih et al. (2013) , then at human level Mnih et al. (2015) — was not new theory but two pieces of engineering that tame the triad’s two instabilities: experience replay and a target network. This chapter is about that engineering — and the overestimation bias that the next refinement, Double DQN, corrects.
From Q-learning to a deep Q-network
Replace the Q-table with a network and fit it to the sampled Bellman optimality target. DQN minimizes, over transitions drawn from a replay buffer ,
where are the target-network weights. As in Chapter 5 this is a semi-gradient method: we differentiate only , treating the target as fixed. Two structural problems would sink naive online training, and DQN answers each:
- Correlated data. Consecutive transitions in a trajectory are highly correlated, violating the i.i.d. assumption gradient descent leans on.
- A moving target. The regression target uses the same network being updated, so every gradient step shifts the target it was chasing — the bootstrap instability of the triad.
Experience replay
The first fix stores each transition in a fixed-capacity buffer and trains on uniformly sampled minibatches rather than the latest transition. Three benefits follow: sampling across many past episodes decorrelates the minibatch toward the i.i.d. regime; each transition is reused many times, improving sample efficiency; and the update distribution becomes the buffer’s mixture rather than the current policy’s trajectory, re-weighting away from the pathological off-policy distributions that drive divergence. The idea is old — it is the model-free, sampled descendant of the prioritized sweeping of Chapter 2 — and its prioritized variant returns shortly.
Target networks
The second fix freezes the bootstrap. DQN keeps a separate copy of the network, holds it fixed while training , and refreshes only every steps (a hard update) or by a slow Polyak average (a soft update). Between refreshes the target is a fixed function, so each interval is an ordinary supervised regression toward a stationary target — exactly the stability the moving-target triad destroyed. The slower moves, the more stable and the slower the learning — the central DQN tuning trade-off.
Overestimation and Double DQN
One bias survives even with replay and a target network: the in the target overestimates. Because the network’s action-values are noisy estimates, taking their maximum is systematically too high.
Let be unbiased estimates of the true values , i.e. for each . Then
with strict inequality whenever two or more actions’ estimates have positive-variance overlap. The bootstrap target therefore inherits a positive bias.
The function is convex (a pointwise maximum of linear maps). Jensen’s inequality for a convex function gives , and the right side is by unbiasedness. Jensen is an equality only where the convex function is affine along the distribution’s support; the has a kink exactly where the maximizing action changes, so any noise that makes the random makes the inequality strict.
Double DQN Hasselt et al. (2016) removes most of this bias by decoupling action selection from evaluation: pick the next action with the online network but evaluate it with the target network,
The selecting and evaluating estimates now have independent errors, so they no longer conspire to inflate the maximum — a one-line change that measurably improves scores.
Dueling, prioritized replay, and Rainbow
Three further refinements round out the family. The dueling architecture Wang et al. (2016) splits the network into a state-value stream and an advantage stream , recombined as , so the agent can learn a state is good without estimating every action precisely. Prioritized experience replay Schaul et al. (2016) samples transitions in proportion to their Bellman-residual magnitude — Chapter 2’s prioritized sweeping, now over replayed transitions — with importance weights to correct the sampling bias. Rainbow Hessel et al. (2018) combines six such improvements (double, dueling, prioritized replay, multi-step returns, distributional values, and noisy exploration) and ablates each, showing they are largely complementary.
From states to pixels
DQN’s headline result was learning from raw Atari frames on the Arcade Learning Environment Bellemare et al. (2013) . The pixel pipeline adds its own engineering: grayscale and downsample each frame, stack four frames so velocity is observable (a single frame is not Markov), skip frames, clip rewards to , and read the stack with a convolutional network. None of this changes the algorithm — it changes the features the same loss is regressed on. Reliable comparison across all this machinery is itself hard — reproducibility studies and standardized implementations Raffin et al. (2021) exist precisely because small details swing results, a theme Week 8 returns to.
The dynamic-programming bridge
DQN is the deadly triad (Chapter 5) survived by engineering rather than dissolved by theory. The regression target is still the sampled Bellman optimality backup of Chapter 1; the two additions each blunt one edge of the triad. Replay re-weights and decorrelates the update distribution — the off-policy edge — and is the model-free heir to prioritized sweeping (Chapter 2). The target network freezes the bootstrap operator for steps — the moving-target edge — converting divergent fixed-point chasing into a sequence of stationary regressions. The discount that guaranteed convergence with a table now only bounds the per-interval target; stability is bought, not proved.
What’s next
- Week 7 changes the object of optimization entirely: instead of learning values and acting greedily, policy-gradient methods parameterize and optimize the policy directly, sidestepping the and its overestimation, and extending naturally to continuous actions.
Exercises
-
(Prove) Show for unbiased , and state when the inequality is strict (Prop. 6.1).
Solution
is convex, so Jensen gives . It is strict whenever the noise makes the random (two actions’ estimates overlap with positive probability), because the is non-affine across the kink where the maximizer switches.
-
(Derive) Write the Double DQN target and explain why it reduces the overestimation of Proposition 6.1.
Solution
. Selection uses , evaluation uses ; their estimation errors are (largely) independent, so the action chosen as best by one network is not automatically assigned an inflated value by the same network. The bias becomes the much smaller bias of evaluating a possibly-suboptimal action.
-
(Compute) A replay buffer of capacity 3 receives transitions in order. Which are stored after , and why does a hard target update at step leave momentarily equal to ?
Solution
A circular buffer of capacity 3 keeps the three most recent, ( overwritten). A hard update copies , so immediately after step the two networks are identical; they diverge again as updates over the next steps while is held fixed.
-
(Implement) In the companion, verify the replay buffer, target-update, and TD-target components, and that DQN learns CartPole well above the random-return baseline within a fixed step budget.
Solution
See
experiments/python/week06/test_dqn.py: circular-buffer overwrite and sample shapes; hard/soft target updates; the done-masked TD target and the Double-DQN selection/evaluation split; the empirical overestimation of the plain max; and a seeded CartPole run whose mean return rises far above the ~22 random baseline. -
(Extend) Add Double and Dueling variants and measure the overestimation gap (the plain-max target minus the Double target) over training.
Solution
The companion exposes
doubleandduelingflags; the plain-max target sits above the Double target early in training (when value estimates are noisiest) and the gap shrinks as the network sharpens — the empirical face of Proposition 6.1.
Companion code
The Week-6 companion lives at experiments/python/week06/ and is the chapter’s first
PyTorch code. Its correctness suite follows the repo’s deep-RL convention: fast,
deterministic component tests for the pieces, plus a seeded simple-environment
convergence check — heavy pixel environments are a deferred @slow showcase, not a
graded test, in line with the 8 GB GPU budget.
dqn.py— a minimal DQN onCartPole-v1: a circularReplayBuffer, an MLPQNetwork(and aDuelingQNetwork), an exposedtd_target(plain and Double), hard/soft target updates, and the training loop, withdouble/duelingflags.test_dqn.py— component-correctness tests (replay overwrite + sample shapes; target-network hard/soft updates; the done-masked Bellman target; the Double-DQN selection/evaluation split; the max-overestimation of Prop. 6.1) plus a seeded CartPole run asserting the mean return clears the random baseline by a wide margin.
# component tests + a seeded CartPole learning check (PyTorch; ~1-2 min on CPU)
PYTHONPATH=. pytest experiments/python/week06/test_dqn.py -q
# worked CartPole training run (prints the learning curve summary)
PYTHONPATH=. python experiments/python/week06/dqn.py --double --episodes 400Policy Gradient Foundations
Optimizing a parameterized stochastic policy directly by gradient ascent on expected return: the policy gradient theorem via the log-derivative trick, REINFORCE, and baselines as variance-reducing control variates. Policy gradients as Monte Carlo sensitivity analysis — and the advantage that bridges to actor-critic.
Policy Gradient Foundations
Where we are. Every method so far learned a value and acted greedily — the of Chapters 4–6. Policy-gradient methods discard that indirection: they parameterize the policy and ascend the gradient of expected return directly. This sidesteps the and its overestimation (Chapter 6), handles stochastic policies and continuous actions natively, and rests on one identity — the log-derivative trick — that turns “differentiate an expectation you can only sample” into “weight samples by the score .” The roadmap’s framing is exact: policy gradients are Monte Carlo sensitivity analysis.
The objective and the score
Let the policy be , differentiable in . A trajectory has return , and the objective is its expectation,
We cannot differentiate by differentiating the reward — the dependence on is through the sampling distribution of , not the integrand. The score function is what carries that dependence, via one identity.
The policy gradient theorem
The gradient of has a famously clean form, due to Sutton et al. Sutton et al. (2000) : an expectation of the score weighted by the action-value, with no derivative of the unknown dynamics anywhere in it.
The gradient of the expected return is
No derivative of the dynamics or the reward appears — only the score of the policy.
Write with trajectory density . Differentiate and apply the log-derivative trick :
In the initial-state and dynamics terms do not depend on , so — the model need not be known or differentiated. That gives the first form. Using causality (an action cannot influence past rewards, for ) replaces by the return-to-go, whose conditional expectation is , giving the second.
The estimator is Monte Carlo sensitivity analysis: it estimates from samples without differentiating the sampled function, by reweighting each sample by its score. It is unbiased and, being Monte Carlo (Chapter 3), high-variance — which the rest of the chapter attacks.
REINFORCE
Sampling the theorem’s expectation gives the REINFORCE algorithm Williams (1992) : roll out episodes under , form the returns-to-go , and ascend
It is unbiased and model-free, the policy-space counterpart of Monte Carlo value estimation — and inherits Monte Carlo’s variance. The single most effective fix is a baseline.
Baselines as control variates
For any function that does not depend on the action,
so subtracting from the return weight in the policy gradient leaves it unbiased, while choosing to track the typical return reduces its variance.
Condition on and average the score over actions:
Hence : subtracting changes the gradient’s variance but not its mean. The variance-minimizing choice makes the weight a centered quantity; taking turns the weight into the advantage .
A baseline is precisely a control variate: a zero-mean term subtracted to shrink variance without moving the estimate. With , the policy gradient becomes — the form every actor-critic method (Week 8) estimates. Learning the baseline is what makes it a critic.
The dynamic-programming bridge
Policy gradients invert the value-based pattern. Chapters 4–6 solved a Bellman fixed point and read off a greedy policy; here the policy is the primal object optimized by gradient ascent, and value functions re-enter only as the baseline/critic that tames variance. Three threads carry forward:
- To actor-critic (Week 8). Learn (or the advantage directly) as the baseline; the policy is the actor, the value the critic. Generalized advantage estimation tunes the bias–variance of , and trust regions (PPO/TRPO) control the ascent step size in policy space.
- To continuous control (Week 9). No over actions is ever taken, so continuous action spaces are immediate — the setting where DDPG, TD3, and SAC live.
- To optimal control (Part II). Differentiating an expected cost through the dynamics is the discrete, stochastic cousin of the adjoint/Hamiltonian sensitivity of Pontryagin’s principle — direct policy search is trajectory optimization with the model replaced by samples.
What’s next
- Week 8 learns the baseline as a critic (actor-critic), tunes the advantage with generalized advantage estimation, and adds trust regions (TRPO/PPO) to bound the policy update — turning REINFORCE’s noisy ascent into a stable, sample-reusing optimizer.
Exercises
-
(Derive) Derive the policy gradient theorem from using the log-derivative trick, and show the dynamics terms drop (Theorem 7.1).
Solution
. Since splits into initial-state, policy, and dynamics terms and only the policy terms carry , — the model cancels.
-
(Prove) Show a state-dependent baseline leaves the policy gradient unbiased, i.e. (Prop. 7.1).
Solution
. Multiplying by (constant in ) and taking the outer expectation over preserves the zero.
-
(Compute) For a softmax policy , compute the score .
Solution
— the feature, weighted by “taken minus probability.” Summed over this is zero (Prop. 7.1), the discrete face of the expected-score identity.
-
(Implement) In the companion, verify the returns-to-go computation, that the expected score is zero (the baseline mechanism), that a baseline reduces gradient variance without bias, and that REINFORCE learns CartPole above the random baseline.
Solution
See
experiments/python/week07/test_reinforce.py: a hand-checked discounted return-to-go; for a softmax network; a bandit where the baselined estimator has strictly lower variance; and a seeded CartPole run whose mean return clears the ~22 random baseline. -
(Extend) Add an entropy bonus to the objective and explain its effect on exploration. (The roadmap’s JAX
jax.gradvariant is deferred to the dedicated JAX track.)Solution
The entropy bonus rewards less-peaked policies, slowing premature convergence to a deterministic policy and sustaining exploration; its gradient adds , pushing toward higher-entropy distributions. It reappears, promoted from a bonus to the objective, in maximum-entropy RL (Week 9, SAC).
Companion code
The Week-7 companion lives at experiments/python/week07/ and is PyTorch
REINFORCE on CartPole-v1, with and without a value baseline.
reinforce.py— a softmaxPolicyNetwork, the discountedcompute_returns(returns-to-go), and a REINFORCE training loop with an optional learned-value baseline and return normalization.test_reinforce.py— component-correctness tests (hand-checked returns-to-go; the expected score that underlies Prop. 7.1; a bandit where the baselined gradient estimator has strictly lower variance) plus a seeded CartPole run learning well above the random-return baseline.
# component tests + a seeded CartPole learning check (PyTorch; ~1-2 min on CPU)
PYTHONPATH=. pytest experiments/python/week07/test_reinforce.py -q
# worked REINFORCE training run (with the value baseline)
PYTHONPATH=. python experiments/python/week07/reinforce.py --baseline --episodes 800Actor-Critic, GAE, PPO, and TRPO
Turning REINFORCE into a stable, sample-reusing optimizer: actor-critic with a learned baseline, generalized advantage estimation as a bias–variance dial, and trust regions (TRPO/PPO) as step-size control in policy space. Why the clipped surrogate works, and why implementation details decide the score.
Actor-Critic, GAE, PPO, and TRPO
Where we are. REINFORCE (Chapter 7) was unbiased but high-variance and strictly on-policy: one noisy gradient step per batch of fresh trajectories, then throw the data away. This chapter turns it into the workhorse of modern on-policy RL by adding three things: a learned critic as the baseline (actor-critic), generalized advantage estimation to tune the advantage’s bias–variance, and a trust region (TRPO/PPO) that bounds how far each update moves the policy — which is what finally lets a batch be reused for several epochs. The roadmap’s framing is the through-line: trust regions are step-size control in policy space.
Actor-critic
Chapter 7 ended with the advantage form of the policy gradient, . Actor-critic makes the baseline a learned function: an actor and a critic trained to predict returns, with the advantage estimated from the critic. Advantage actor-critic (A2C) updates both together — the critic by regressing toward the returns, the actor by ascending the score weighted by the critic’s advantage. Konda and Tsitsiklis Konda & Tsitsiklis (2000) established the two-timescale convergence of actor-critic with a linear critic; the critic plays the role of approximate policy evaluation in a sampled, function-approximated generalized policy iteration.
Generalized advantage estimation
How should the advantage be estimated? The one-step TD residual is itself a low-variance, high-bias advantage estimate; the full Monte Carlo advantage is the reverse. Generalized advantage estimation Schulman et al. (2016) interpolates with an exponential weighting.
The generalized advantage estimator
satisfies the backward recursion
Its endpoints are , giving (low variance, high bias), and , giving (the Monte Carlo advantage: high variance, low bias).
Split the defining sum at its first term:
For , telescopes: writing , the value terms cancel in pairs, leaving .
The recursion is what the companion computes in one backward pass. Intermediate (commonly ) usually beats both endpoints — the same lesson as -step TD, now applied to the advantage that weights the policy gradient.
Trust regions: TRPO and PPO
REINFORCE and A2C take one gradient step per batch because the advantage estimate is only valid near the policy that generated the data; a large step can collapse performance. The fix is to bound the update — to control the step size in policy space rather than parameter space.
TRPO Schulman et al. (2015) makes this literal: maximize the importance-weighted surrogate , with ratio , subject to a trust-region constraint . The KL ball is the trust region; within it the linearized objective is reliable.
PPO Schulman et al. (2017) replaces the hard constraint with a cheaper clipped surrogate,
The makes a pessimistic lower bound on the unclipped surrogate: when an advantage is positive, the objective stops rewarding increases in once (its gradient there is zero); when negative, it stops once . Either way there is no incentive to push the policy far from in a single update, so PPO can safely take several epochs of minibatch updates per batch — the sample reuse REINFORCE lacked.
Implementation matters
A sobering empirical fact closes the family. Engstrom et al. Engstrom et al. (2020) showed that much of PPO’s advantage over TRPO comes not from the clipped objective but from code-level details — advantage normalization, value-function clipping, reward scaling, learning-rate annealing, orthogonal initialization — applied alongside it. Together with the broader reproducibility findings of Henderson et al. Henderson et al. (2018) , the lesson is that on-policy deep RL results must be read with the implementation, not just the algorithm, in view. The companion therefore tests the components (the GAE recursion, advantage normalization, the clip) and checks learning on a simple task, rather than chasing a benchmark number.
The dynamic-programming bridge
Actor-critic completes the generalized-policy-iteration picture under approximation. The critic is approximate policy evaluation (Chapter 1’s , learned from samples); the gradient actor is approximate improvement. Where policy iteration took the full greedy jump to , the actor takes a small step, and the trust region (TRPO’s KL ball, PPO’s clip) is exactly the step-size control that keeps improvement reliable when evaluation is noisy and local. Two bridges:
- To continuous control (Week 9). Everything here is on-policy and stochastic; Week 9 turns to off-policy continuous control (DDPG, TD3, SAC), trading sample reuse-by-replay for the on-policy stability bought here by trust regions.
- To optimal control (Part II). A trust region on the update is a regularized step — the policy-space analogue of a line search or a Levenberg–Marquardt damping in optimization, and a cousin of MPC’s receding horizon as a bound on how far ahead a single decision commits.
What’s next
- Week 9 leaves on-policy methods for off-policy continuous control: the deterministic policy gradient (DDPG), its twin-critic fix (TD3), and maximum-entropy RL (SAC) — where the entropy bonus of Chapter 7 becomes the objective.
Exercises
-
(Derive) Derive the GAE recursion from the exponential sum, and show gives the Monte Carlo advantage (Prop. 8.1).
Solution
Split the sum at : . At the value terms in telescope to .
-
(Prove) Show is a lower bound on the unclipped surrogate , and identify where its gradient with respect to is zero.
Solution
pointwise, so the expectation is a lower bound. For the clip caps the term at once , where ; for it floors at once , again with zero gradient. Inside the gradient is .
-
(Compute) With , , and TD residuals at the end of an episode (bootstrap zero), compute .
Solution
Backward: ; ; . (The companion’s
compute_gaereproduces these.) -
(Implement) In the companion, verify the GAE recursion matches the exponential sum and that equals returns minus values; that advantage normalization produces mean-0/unit-variance advantages; that the PPO clip flattens the objective outside ; and that PPO learns CartPole above the random baseline.
Solution
See
experiments/python/week08/test_ppo.py:compute_gaevs the brute-force ; the telescoping identity; the normalization statistics; the clip’s value/gradient outside the range; and a seeded PPO CartPole run clearing the ~22 random baseline. -
(Extend) Sweep the PPO clip range and add KL early stopping; compare stability across seeds.
Solution
Smaller tightens the trust region (more stable, slower); larger loosens it (faster, riskier). KL early stopping halts the epoch loop once the policy has moved a target KL from , a direct enforcement of the trust region the clip only approximates — the companion’s
--clip/--target-klflags expose both.
Companion code
The Week-8 companion lives at experiments/python/week08/ and is PyTorch A2C and
PPO on CartPole-v1, sharing one actor-critic network.
ppo.py—compute_gae(the backward recursion), anActorCriticnetwork, theppo_clip_objective, and a PPO/A2C training loop with advantage normalization and a configurable clip range and epoch count.test_ppo.py— component-correctness tests (compute_gaevs the closed-form exponential sum; the = returns − values identity; advantage normalization; the PPO clip’s value and zero gradient outside ) plus a seeded PPO CartPole run learning above the random baseline.
# component tests + a seeded CartPole learning check (PyTorch; ~1-2 min on CPU)
PYTHONPATH=. pytest experiments/python/week08/test_ppo.py -q
# worked PPO training run on CartPole
PYTHONPATH=. python experiments/python/week08/ppo.py --updates 150Off-Policy Continuous Control: DDPG, TD3, and SAC
Off-policy actor-critic for continuous actions: the deterministic policy gradient (DDPG), the twin-critic overestimation fix (TD3), and maximum-entropy RL (SAC). Why the soft-optimal policy is Boltzmann in the action-value, and how maximum-entropy RL is KL-regularized optimal control — the bridge from learning to Part II.
Off-Policy Continuous Control: DDPG, TD3, and SAC
Where we are. Weeks 7–8 optimized stochastic policies on-policy. This chapter — the last of the RL foundations — turns to off-policy continuous control, where two ideas dominate the model-free baselines. First, the deterministic policy gradient (DDPG) makes continuous actions tractable by pushing the gradient through a differentiable critic instead of sampling them. Second, maximum-entropy RL (SAC) augments the reward with policy entropy, which both stabilizes learning and reveals a deep identity: maximum-entropy RL is KL-regularized optimal control — the bridge out of learning and into Part II. Between them, TD3 fixes the overestimation that Chapter 6 first diagnosed, now arising from the critic’s own bootstrap.
The deterministic policy gradient
With a continuous action space the stochastic policy gradient (Chapter 7) must average the score over actions — expensive and high-variance. A deterministic policy avoids the action integral, and its gradient flows through the critic by the chain rule.
For a deterministic policy and its action-value , under mild regularity the gradient of the off-policy objective is
where is the (off-policy) state distribution. The policy is improved by pushing its output up the critic’s action-gradient.
This is the continuous-action analogue of greedy improvement: where a discrete agent takes , the deterministic actor takes a gradient step in toward larger . Silver et al. Silver et al. (2014) proved the theorem (as the zero-variance limit of the stochastic gradient); Lillicrap et al. Lillicrap et al. (2016) turned it into DDPG — the deterministic actor and critic trained off-policy with the replay buffer and target networks of Chapter 6, and exploration noise added to the actor’s output.
Overestimation returns: TD3
DDPG inherits the deadly-triad fragility and the overestimation bias of Chapter 6 — now produced by the critic bootstrapping on its own optimistic estimates. TD3 Fujimoto et al. (2018) applies three fixes, the first echoing Double DQN:
- Twin critics, take the minimum. Train two critics and form the target with — clipped double Q-learning, a continuous cousin of Double DQN that caps the upward bias of Proposition 6.1.
- Delayed policy updates. Update the actor (and targets) less often than the critics, so the policy chases a more settled value.
- Target policy smoothing. Add clipped noise to the target action, regularizing the critic against sharp peaks it could otherwise exploit.
The first is the load-bearing one: taking the minimum of two independent critics systematically underestimates, which is far safer for a bootstrapped target than the overestimate the single-critic max produces.
Maximum-entropy RL and SAC
A different idea reshapes the objective itself. Maximum-entropy RL adds the policy’s entropy to the reward, scaled by a temperature :
The agent is rewarded for acting well and for staying stochastic — sustaining exploration and robustness. Soft actor-critic Haarnoja et al. (2018) is the off-policy actor-critic for this objective, with an automatically tuned temperature Haarnoja et al. (2019) . The one-step soft problem has a clean optimum.
Maximizing over distributions gives the Boltzmann policy
with optimal soft value . As this recovers the greedy and the ordinary value.
Write and maximize subject to . The Lagrangian’s stationarity in gives , so , i.e. . Normalizing gives the Boltzmann form; substituting back gives , the log-sum-exp “soft maximum.” As the soft max and greedy.
The entropy bonus of Chapter 7 has been promoted from a heuristic to the objective, and its optimum is a temperature-controlled softmax over the action-value.
The dynamic-programming bridge
Maximum-entropy RL is where learning rejoins control. The soft value is the optimal cost-to-go of a KL-regularized control problem: maximizing reward minus against a reference yields exactly the Boltzmann policy of Proposition 9.1, and Todorov’s linearly-solvable MDPs exploit precisely this — under the exponential transform the soft Bellman equation becomes linear. Three threads close Part I:
- Continuous-action improvement is the deterministic actor (DPG) or the soft Boltzmann policy (SAC), replacing the discrete — approximate policy iteration (Chapter 1) in a continuum.
- Overestimation control (TD3’s twin-min) is the same bias management as Double DQN (Chapter 6), now load-bearing because the bootstrap runs through a critic.
- To Part II. KL-regularized control, the maximum-entropy LQR with its closed form, and the deterministic limit () that is classical optimal control are the entry points to LQR (Week 13) and MPC (Week 15) — the model-based, deterministic side of the same fixed point.
What’s next
- Week 10 steps back to ask where RL has actually worked in the real world — a survey of robotics successes (locomotion, manipulation, flight, plasma control) and the conditions that made them possible.
- Part II (Week 11+) then changes register entirely, to control theory: stability, LQR, and model predictive control — met now from the RL side, and rejoined with it in Part III.
Exercises
-
(Derive) Starting from , derive the deterministic policy gradient by the chain rule (Theorem 9.1).
Solution
by the chain rule (the explicit -dependence of is held fixed); taking the expectation over gives Theorem 9.1. The state distribution may be off-policy, which is why DDPG can learn from a replay buffer.
-
(Prove) Show the maximum-entropy one-step optimal policy is with soft value (Prop. 9.1).
Solution
Maximize under ; stationarity gives , so . Substituting the normalized policy back yields the log-sum-exp soft value. The limit recovers the hard .
-
(Compute) A target state has twin-critic estimates , for the target action. What value does TD3 use, and why is the minimum the safer choice for a bootstrap target?
Solution
TD3 uses . The single-critic max/overestimate (Prop. 6.1) compounds through bootstrapping; taking the minimum of two independent estimates biases downward, and a slight underestimate does not amplify across the backup the way an overestimate does.
-
(Implement) In the companion, verify the twin-critic minimum lowers the target versus a single critic; that target-policy-smoothing noise is clipped to range; the Polyak soft target update; and that minimal TD3 learns Pendulum above the random return.
Solution
See
experiments/python/week09/test_td3.py: the clipped-double-Q target equals the per-sample minimum of the twin critics (≤ either); the smoothing noise and target action respect their clip bounds; the Polyak update matches its closed form; and a seeded TD3 run onPendulum-v1clears the random-return baseline by a wide margin. -
(Extend) Sweep the SAC temperature and relate the limit (greedy) and large (uniform). (The roadmap’s JAX/Brax SAC baseline is deferred to the dedicated JAX track.)
Solution
Small concentrates the Boltzmann policy on the (exploitation, recovering ordinary RL); large flattens it toward uniform (maximal exploration). Automatic temperature tuning Haarnoja et al. (2019) adjusts to hold a target entropy rather than fixing it by hand.
Companion code
The Week-9 companion lives at experiments/python/week09/ and is a minimal TD3 on
Pendulum-v1 (the chapter’s testable centerpiece), with Stable-Baselines3 named as the
reference baseline.
td3.py— a continuous-actionReplayBuffer, a deterministicActorand twinCritics, the exposedtd3_target(clipped double-Q with target-policy smoothing), Polyaksoft_update, and the training loop. Pure PyTorch.test_td3.py— component-correctness tests (the twin-critic minimum lowers the target; smoothing-noise and target-action clipping; the Polyak update’s closed form) plus a seededPendulum-v1run learning well above the random return.
# component tests + a seeded Pendulum learning check (PyTorch; ~1-2 min on CPU)
PYTHONPATH=. pytest experiments/python/week09/test_td3.py -q
# worked minimal-TD3 training run on Pendulum
PYTHONPATH=. python experiments/python/week09/td3.py --steps 40000Reinforcement Learning in the Real World: A Robotics Survey
Where reinforcement learning has actually worked on real hardware — dexterous manipulation, legged locomotion, champion drone racing, and tokamak plasma control — and the recipe behind those successes: abundant simulation, domain randomization, and RL reserved for where models are hard or adaptation is required. The empirical case for RL, and why it sets up Part II.
Reinforcement Learning in the Real World: A Robotics Survey
Where we are. Part I built the algorithms — dynamic programming, Monte Carlo and temporal difference, deep value learning, and policy-gradient and actor-critic methods through continuous control. This capstone asks the empirical question those chapters deferred: where has reinforcement learning actually worked on real hardware, and what conditions made it work? The honest answer is both encouraging and narrowing — a handful of genuine, high-profile successes that share a remarkably consistent recipe, and which together explain when to reach for RL and when classical control still wins. This is a reading-and-synthesis week: no new algorithm, a small evidence table, and the argument it supports.
The cases
Dexterous manipulation. OpenAI’s Rubik’s-Cube hand Akkaya et al. (2019) trained a Shadow Hand entirely in simulation and transferred to physical hardware via automatic domain randomization (ADR) — progressively widening the distribution of simulated physics (friction, masses, latencies) until the real robot looked like just another sample. The policy solved a Rubik’s cube one-handed despite never touching a real cube during training.
Legged locomotion. The most mature success story. Lee et al. Lee et al. (2020) trained a blind quadruped to traverse challenging terrain by teacher–student distillation: a privileged teacher with full state trains a proprioception-only student deployable on hardware. Miki et al. Miki et al. (2022) added exteroception, producing robust perceptive locomotion over stairs, gaps, and obstacles outdoors. Radosavovic et al. Radosavovic et al. (2024) carried the same sim-to-real recipe to a full-size humanoid, walking zero-shot in outdoor environments.
Agile flight. Kaufmann et al. Kaufmann et al. (2023) trained an RL policy that beat human world champions at physical first-person-view drone racing — a regime where split-second control at the edge of the dynamics envelope defeats hand-tuned controllers.
Scientific and industrial control. The standout non-locomotion case: Degrave et al. Degrave et al. (2022) used deep RL to magnetically control the plasma shape in a real tokamak, coordinating dozens of control coils against many simultaneous constraints — a problem where accurate first-principles control is genuinely hard and the payoff of learned control is large.
Human-in-the-loop methods (collecting corrective feedback during training) are an active frontier for precise manipulation, pushing RL toward sub-millimeter industrial tasks; the cross-cutting survey of deployed systems by Tang et al. Tang et al. (2025) catalogues these and the recurring sim-to-real patterns.
An evidence table
The roadmap’s deliverable for this week is an evidence table, not code — laying the cases side by side exposes the shared recipe.
| System | Task | Trained in | Real hardware | Sim-to-real / adaptation | Control baseline beaten | |---|---|---|---|---|---| | Rubik’s hand Akkaya et al. (2019) | dexterous manipulation | MuJoCo sim | Shadow Hand | automatic domain randomization | no prior model-based in-hand dexterity controller | | Quadruped Lee et al. (2020) | blind rough-terrain locomotion | rigid-body sim | ANYmal | teacher–student distillation | model-based gait controllers | | Quadruped (wild) Miki et al. (2022) | perceptive locomotion | rigid-body sim | ANYmal | proprio + exteroception, randomization | model-based perceptive control | | Humanoid Radosavovic et al. (2024) | bipedal walking | sim | full-size humanoid | zero-shot sim-to-real | model-based whole-body control | | Drone racing Kaufmann et al. (2023) | agile FPV flight | sim + identified dynamics | racing quadrotor | system identification + randomization | human world champions (and prior autonomous baselines) | | Tokamak Degrave et al. (2022) | plasma magnetic control | physics simulator | TCV tokamak | sim-to-real on a calibrated model | conventional multi-loop controllers |
The empirical case for RL
Read down the table and the same three conditions recur — the conditions under which RL is the right tool Tang et al. (2025) :
- Model accuracy is hard. Contact-rich locomotion, dexterous manipulation, and plasma dynamics resist accurate first-principles models. RL learns from interaction what is painful to derive.
- Adaptation is required. Terrain, disturbances, and hardware variation demand a policy robust across conditions; domain randomization turns that need into a training distribution the policy generalizes over.
- Simulation is abundant. Every case generates its training data in a fast, parallel simulator — the millions of samples RL needs are free there and ruinously expensive on hardware.
Where these fail to hold — no faithful simulator, safety-critical systems with no simulation budget, or problems with good analytic models — classical and optimal control remain the better choice. The successes are real but conditional, and naming the conditions is the point of the survey.
The simulation paradox, and the bridge to Part II
The deepest lesson is a paradox. These are triumphs of model-free policy learning — the deployed policy plans through no learned dynamics model — yet not one of them learned on hardware from scratch. Each trained inside a simulator (a model) and randomized it to cross the reality gap. Model-free RL conquers the physical world precisely by leaning on an abundant, deliberately imperfect model. Stated that way, the question Part II answers comes into focus: when you already have a good model, why learn around it? Control theory — Lyapunov stability, the LQR’s closed-form optimal feedback, model predictive control’s online re-optimization — exploits the model directly, with guarantees RL cannot offer. Part III then fuses the two: MPC that learns its model or cost, and RL warm-started or constrained by a controller. The robotics successes are where the model-free spine of Part I meets reality; the model-based spine of Part II is the other half of the same fixed point.
What’s next
- Part II (Week 11+) changes register from learning to control theory: dynamical systems and Lyapunov stability, the linear-quadratic regulator as the exactly-solvable optimal control problem (the Bellman fixed point in closed form), and model predictive control as online approximate dynamic programming. The discount-contraction spine of Part I reappears as the Riccati equation and the receding horizon.
Exercises
-
(Compute) Add one more deployed RL system to the evidence table (e.g. a warehouse, autonomous-driving, or data-center cooling deployment) and fill all six columns from its paper. Which of the three conditions does it satisfy?
Solution
Most deployed cases satisfy all three (hard model, adaptation, abundant sim); data-center cooling is the interesting partial case — a learned model substitutes for a hard-to-build simulator, stretching condition 3. The exercise is to make the classification explicit and defend it from the paper’s methods section.
-
(Derive) From the six cases, state the three enabling conditions precisely, and give a concrete robotics task that fails at least one — predicting that classical control should win there.
Solution
A safety-critical task with no faithful simulator and a tight real-data budget (e.g. a one-off surgical manipulator) fails conditions 1 and 3: RL’s sample appetite cannot be met and the reality gap cannot be closed, so model-based / optimal control with formal guarantees is the appropriate tool.
-
(Extend) Implement a tiny domain-randomization toy: train a policy (e.g. the Week-7 REINFORCE or Week-9 TD3 companion) on a Gymnasium env whose dynamics are randomized each episode (mass, gravity, or action scale), and measure its robustness to a held-out dynamics setting versus a policy trained without randomization.
Solution
Randomizing a physics parameter each reset trains a policy over a distribution of dynamics; on a held-out setting it should degrade far less than the non-randomized policy, reproducing in miniature the sim-to-real mechanism every case above relies on. This is the one optional code task of an otherwise reading-only week.
-
(Extend) Pick one case and argue where a Part-II model-based controller (LQR or MPC) could replace or augment the learned policy. What would each approach require?
Solution
The tokamak is the natural candidate: a calibrated plasma model already exists, so an MPC could in principle re-optimize the coil currents online — at the cost of solving a constrained optimization every control step, which is exactly what RL amortizes into a fast policy. The trade is online compute and model fidelity (MPC) versus training cost and the reality gap (RL) — the Part III hybrid uses both.
State-Space Models and Transfer Functions
The entry to control theory: the linear state-space model, the transfer function, and their equivalence. Two views of one dynamical system, the state-similarity invariance that makes the transfer function the coordinate-free object, and the discrete-time model that is exactly the MDP dynamics control assumes known.
State-Space Models and Transfer Functions
Where we are. Part I learned policies and values from interaction, with the dynamics unknown or only sampled. Part II turns to control theory, which starts from the opposite end — an explicit model of the dynamics — and asks what optimal feedback that model permits. The foundational object is the linear state-space model , $y = \outputmat\statevec
- \feedmat uH(s) = \outputmat(s I - \statemat)^-1\inputmat + \feedmat$. They are two views of one system. This chapter sets up that object — and shows its discrete-time form is exactly the known MDP dynamics that LQR (Week 13) will solve in closed form.
The linear state-space model
A continuous-time LTI system with state , input , and output is
with , , , . Its discrete-time counterpart, sampled at step , is , .
The running example is the mass–spring–damper : taking the state gives , , and if we measure position. A second-order mechanical law has become a first-order vector ODE — the form every method in Part II acts on.
The transfer function
Laplace-transforming the state equation at zero initial condition and eliminating the state gives the input–output map directly.
The transfer function of is the rational matrix
mapping input to output in the Laplace domain, . Its poles are the eigenvalues of (those not cancelled by zeros), and its zeros are the frequencies it blocks.
For the mass–spring–damper the single-input single-output transfer function is — the poles are the roots of the characteristic polynomial, i.e. the eigenvalues of , exactly the natural frequencies of the oscillator. Åström and Murray \AAström & Murray (2021) develop both views and their interplay; the state-space form carries the internal dynamics, the transfer function the external behaviour.
Two views, one system
The two representations are equivalent, with one asymmetry worth making precise: the transfer function is unique, but the state-space realization is not — any invertible change of state coordinates leaves the input–output behaviour untouched.
For any invertible , the coordinate change produces the system with the same transfer function .
Substitute into Definition 11.1: and , so the transformed matrices are as stated. Its transfer function is
The similarity transform cancels, leaving unchanged.
So the state-space model is a coordinate choice on the same dynamics, and the transfer function is the coordinate-free invariant. The reverse direction — building a state-space model from a transfer function — is realization, and its non-uniqueness (canonical forms) is the companion’s round-trip check.
Discretization: the bridge to a step map
Control plants are continuous, but computation and the MDP view are discrete. Exact zero-order-hold (ZOH) discretization at step — holding constant across the interval — gives
the matrix exponential of . The cheap alternative, forward Euler, takes — the first two terms of that exponential, accurate only for small . Either way the result is a deterministic step map.
The dynamic-programming bridge
That step map closes the loop with Part I. is precisely a Markov decision process’s transition — deterministic, linear, and known — where Chapters 1–10 had a stochastic kernel learned from samples. Control theory’s premise is that the model is in hand, so the Bellman recursion can be solved exactly rather than approximated from experience. Three threads run forward from here:
- To stability and structure (Week 12). Before designing any controller, ask what the model permits: stability from the eigenvalues of , and whether the input can steer and the output can observe the full state.
- To LQR (Week 13). Put a quadratic cost on this linear model and the Bellman equation has a closed-form solution — the Riccati equation — the exact dynamic-programming fixed point Chapter 1’s HJB aside promised.
- To SSMs (Week 24). The very same and its ZOH discretization are a structured-state-space neural layer (S4, Mamba); the control plant and the sequence model share one skeleton.
What’s next
- Week 12 asks what can be known about a state-space model before designing a controller: stability (eigenvalue locations, Lyapunov), and the structural properties of controllability and observability that decide whether control and estimation are even possible.
Exercises
-
(Derive) From with state , derive the matrices and the transfer function .
Solution
and give the stated ; measuring position gives . Then , since .
-
(Prove) Show the transfer function is invariant under a state-similarity transform (Prop. 11.1), identifying where cancels.
Solution
The transformed system is ; using and inverting, the and on either side of cancel against and , returning .
-
(Compute) For , , , , compute and its poles.
Solution
, and . Poles at — the eigenvalues of , both in the left half-plane (stable, as Week 12 will formalize).
-
(Implement) In the companion, verify the SS→TF→SS round-trip preserves the transfer function, the mass–spring–damper TF matches , and the step response settles to the DC gain .
Solution
See
experiments/python/week11/test_state_space.py:python-controlconverts SS↔TF (round-trip preserves the rational function up to a state similarity); the mass–spring–damper TF coefficients match the analytic form; and the unit-step final value equals the final-value-theorem prediction . -
(Extend) Compare exact ZOH () against forward Euler (): how does the discretization error scale with ?
Solution
ZOH is exact for piecewise-constant input; Euler is its first-order truncation, with error per step (it drops the and higher terms of the exponential). The companion shows the gap vanishing as and growing — eventually destabilizing Euler — for large .
Companion code
The Week-11 companion lives at experiments/python/week11/ and is the first control
companion (Python, on scipy + the python-control library).
state_space.py— builds the mass–spring–damper state-space model, converts SS↔TF (python-control), simulates impulse/step/forced responses, and discretizes via exact ZOH (scipy.linalg.expm) and forward Euler.test_state_space.py— mathematical-correctness tests: the SS→TF→SS round-trip preserves the transfer function; the mass–spring–damper TF equals ; the step response settles to the DC gain ; ZOH equals while Euler is its first-order truncation; and the transfer function is invariant under a random state-similarity transform (Prop. 11.1).
# core algorithms + correctness tests (scipy + python-control)
PYTHONPATH=. pytest experiments/python/week11/test_state_space.py -q
# worked mass-spring-damper SS/TF + response plots (saved locally, not committed)
PYTHONPATH=. python experiments/python/week11/state_space.py --plotStability, Controllability, and Observability
The structural properties of a linear model knowable before any controller exists: internal stability via eigenvalues and the Lyapunov equation, controllability and observability as reachability and state-identifiability, and the duality that makes them one theory — and makes the LQR regulator and the Kalman estimator one computation.
Stability, Controllability, and Observability
Where we are. Week 11 built the linear state-space model and showed the transfer function is its coordinate-free invariant. Before designing any controller, three structural questions decide what is achievable on that model: is it internally stable; can the input steer the whole state (controllability); can the output reconstruct the whole state (observability)? These are the linear-systems analogues of reachability and identifiability in reinforcement learning — they bound what any policy or estimator can do, before optimality is even on the table. LQR and the Kalman filter (Week 13) will need exactly the mild weakenings of these properties.
Internal stability
The autonomous system (zero input) is asymptotically stable if as from every initial state. Its discrete-time counterpart is asymptotically stable if for every .
For a linear system, asymptotic stability is decided entirely by the spectrum of .
The continuous-time system is asymptotically stable iff every eigenvalue of has strictly negative real part — is Hurwitz, . The discrete-time system is asymptotically stable iff every eigenvalue lies strictly inside the unit disk — is Schur, the spectral radius .
The reason is the modal decomposition: solutions of are combinations of over the eigenvalues (with polynomial factors at repeated eigenvalues), and iff ; in discrete time the modes are , which vanish iff .
Eigenvalues answer the question but require an eigendecomposition. The Lyapunov equation gives an equivalent algebraic certificate — and it is the template for the Riccati equation of Week 13.
is Hurwitz iff for every symmetric the Lyapunov equation
has a unique solution , and that is symmetric positive definite. Then is a Lyapunov function: and along every nonzero trajectory.
(, the construction.) Suppose is Hurwitz and fix . Define
Hurwitzness gives for some , so the integrand decays exponentially and the integral converges; is symmetric because is. It is positive definite: for , since and . Finally it solves the equation:
The Lyapunov-function claim follows by differentiating along : . The converse — a positive-definite forcing the spectrum into the open left half-plane — is the standard direction in Sontag (1998) .
So stability has two faces: a spectral test (eigenvalues) and an algebraic certificate (a quadratic energy that strictly decreases). The Lyapunov view generalizes to nonlinear systems (Week 14) and, with a control term added, becomes the Riccati equation that solves LQR (Week 13).
Controllability
The pair is controllable if for any initial state and any target there is an input on some finite interval that drives the state from to . Equivalently, every state is reachable from the origin.
with is controllable iff the controllability matrix
has full row rank, .
Only powers up to appear: by the Cayley–Hamilton theorem is a linear combination of , so higher powers add no new directions. An equivalent test uses the controllability Gramian , which is positive definite iff is controllable; for Hurwitz the infinite-horizon Gramian solves a Lyapunov equation , tying controllability back to the previous section.
Observability
Observability is the same question asked of the output map: can the measurements pin down the state?
The pair is observable if the initial state can be uniquely determined from the output over any finite interval (the input being known).
with , is observable iff the observability matrix
has full column rank, .
The two rank conditions are visibly mirror images — stacks horizontally, stacks vertically. That mirror is not a coincidence.
Duality
is observable iff is controllable; dually, is controllable iff is observable. Concretely, the observability matrix of is the transpose of the controllability matrix of the dual pair,
Write the dual controllability matrix, and transpose its blocks one at a time:
Transposing turns the horizontal blocks into vertical ones, . Since rank is invariant under transposition, , and the rank conditions of Theorems 12.3–12.4 give the equivalence.
Duality halves the theory: every controllability result has a free observability twin. It is also why LQR (state feedback) and the Kalman filter (state estimation) are the same Riccati computation run on dual systems — the deepest structural fact Week 13 will exploit.
The structural bridge to learning
These properties are the control-theoretic statements of limits that also bound reinforcement learning:
- Controllability ↔ reachability. An uncontrollable mode is a direction of state space no input — and therefore no policy — can affect. It is the linear, exact version of the reachable-set question that determines what any RL agent can possibly accomplish on a system.
- Observability ↔ identifiability. An unobservable mode is a latent direction the outputs never reveal, so no estimator can recover it from data. This is precisely the gap between a fully observed MDP and a POMDP, where the agent must act on a belief over hidden state.
- The weakenings LQR needs. Optimal control does not require full controllability/observability, only stabilizability (every uncontrollable mode is already stable) and detectability (every unobservable mode is already stable). These are the exact conditions under which the dynamic-programming value function of Week 13 exists and yields a stabilizing policy — a structural prerequisite, checked before any optimization, for the Bellman recursion to have a well-behaved fixed point.
What’s next
- Week 13 (LQR/LQG). Put a quadratic cost on the controllable linear model and the Bellman equation collapses to the algebraic Riccati equation — the Lyapunov equation of this chapter with a control term subtracted. Stabilizability and detectability are exactly what make its stabilizing solution exist; duality makes the optimal regulator and the optimal estimator one calculation. This is where dynamic programming and control theory become the same equation.
Exercises
-
(Compute) For , decide continuous-time (Hurwitz) and discrete-time (Schur) asymptotic stability.
Solution
The eigenvalues are (triangular matrix). Both have , so is Hurwitz and the flow is asymptotically stable. As a discrete map, and are not inside the unit disk, so is not Schur and is unstable. The same matrix is stable as a flow but unstable as a map — stability is a property of the system type, not of alone.
-
(Prove) With , solving for , show along and conclude asymptotic stability.
Solution
for . A positive-definite function strictly decreasing along every trajectory forces (Lyapunov’s direct method), so the origin is asymptotically stable — without computing a single eigenvalue.
-
(Compute) For , , form and decide controllability.
Solution
, which has rank , so is uncontrollable. The second mode (the eigendirection) has no input coupling, so no can move it. Because that mode is already stable, the system is still stabilizable — the weaker property LQR needs.
-
(Prove) Show , and hence observability of is equivalent to controllability of .
Solution
As in Proposition 12.1: , so transposing the horizontal blocks of produces the vertical observability stack . Rank is invariant under transposition, so the two full-rank conditions coincide.
-
(Implement) In the companion, verify that the controllable/uncontrollable and observable/unobservable examples have the predicted ranks, that the Lyapunov solution is positive definite iff is Hurwitz, and that duality holds as a rank equality.
Solution
See
experiments/python/week12/test_structural.py:is_controllable/is_observablematch the Kalman rank conditions;lyapunov_solvereturns a positive-definite for the Hurwitz oscillator and an indefinite for an unstable (the certificate failing exactly when stability does); andobservability_matrix(A.T, C.T)equalscontrollability_matrix(A, C).T. -
(Extend) The rank tests are exact in arithmetic but decided numerically by a singular-value threshold. Show that the verdict of
numpy.linalg.matrix_rankon a controllable system depends on the tolerance convention: scale the input by and compare numpy’s default (relative) tolerance against a fixed absolute one.Solution
Scaling the input column by shrinks every singular value of in proportion, so stays full rank for every . numpy’s default tolerance is relative — — hence scale-invariant: it reports rank at every . A fixed absolute threshold tells a different story: once the smallest singular value drops below it, the same controllable system reads as rank-deficient. The companion’s
--scaling-demoprints both verdicts side by side (the default stays ; the absolute one flips to , then ). The lesson: controllability is binary in exact arithmetic but graded in finite precision, and “numerically uncontrollable” names a chosen tolerance, not the system — the Gramian’s smallest eigenvalue is the tolerance-free measure of how controllable a system is.
Companion code
The Week-12 companion lives at experiments/python/week12/ (Python, on scipy +
numpy, cross-checked against python-control).
structural.py— Hurwitz / Schur stability tests; the Lyapunov solver for (scipy.linalg.solve_continuous_lyapunov); controllability and observability matrices with their rank tests; the controllability Gramian; and a built (un)controllable / (un)observable dual pair.test_structural.py— mathematical-correctness tests: the stability tests agree with the eigenvalues; the Lyapunov is positive definite iff is Hurwitz, with residual ; the rank conditions classify the controllable/observable examples and their rank-deficient duals; the Gramian solves and is positive definite iff controllable; and duality holds as .
# structural algorithms + correctness tests (scipy + python-control cross-check)
PYTHONPATH=. pytest experiments/python/week12/test_structural.py -q
# worked summary table for several small systems + the rank-under-scaling demo
PYTHONPATH=. python experiments/python/week12/structural.py --scaling-demoLinear-Quadratic Regulation: The Exact Dynamic Program
The linear-quadratic regulator as exact dynamic programming: a quadratic value function, the Riccati recursion as Chapter 1's Bellman optimality equation in coordinates, the linear-feedback optimal policy, the infinite-horizon algebraic Riccati equation, and the LQG separation principle — with Doyle's warning that optimal output feedback carries no guaranteed stability margins.
Linear-Quadratic Regulation: The Exact Dynamic Program
Where we are. Weeks 11–12 built the linear model and the structural properties — stability, controllability, observability — that say what control is possible. Now we put a cost on the model and ask for the best control. The linear-quadratic regulator (LQR) is the one optimal-control problem dynamic programming solves in closed form, and it is exactly Chapter 1’s Bellman optimality equation specialized to linear dynamics and quadratic cost. The “DP bridge” promised since Chapter 1 is paid here: the value function is a quadratic, value iteration becomes the Riccati recursion, and the optimal policy is linear state feedback . Bellman, Riccati, and feedback control turn out to be one calculation.
The LQR problem
For the discrete-time linear system , the finite-horizon LQR problem is to choose minimizing the quadratic cost
with state-cost , control-cost , and terminal cost . The infinite-horizon problem takes with no terminal term, minimizing .
makes every control expensive, so the minimizer is unique and finite; penalizes leaving the origin. This is a Markov decision process (Chapter 1) with a known deterministic linear kernel and a quadratic cost in place of a reward.
LQR is exact dynamic programming
The optimal cost-to-go of Definition 13.1 is the quadratic , where runs the backward Riccati recursion
and the optimal policy is the linear state feedback with time-varying gain
Backward induction on the Bellman optimality equation .
Base. , so .
Step. Assume . Substituting and expanding the quadratic in ,
The Hessian in is (since , ), so the minimizer is the stationary point
Substituting back (completing the square) leaves a pure quadratic in , , whose matrix is exactly the Riccati recursion above. The quadratic form is preserved, closing the induction.
The proof is Chapter 1’s value iteration run on a quadratic ansatz. Every step is one application of the Bellman optimality operator; the minimization is exact (a quadratic in ), not sampled or approximated, because the model is known and the cost is quadratic. The optimal value, the optimal policy, and the optimal cost all fall out of one backward sweep.
Infinite horizon: the algebraic Riccati equation
Run the recursion backward from a far horizon and settles to a constant.
If is stabilizable and is detectable, then as the Riccati iterates converge, , to the unique symmetric positive-semidefinite solution of the discrete algebraic Riccati equation (DARE)
The optimal policy is the stationary feedback with , and the closed loop is asymptotically stable (Schur).
The hypotheses are exactly Week 12’s structural properties: stabilizability (every uncontrollable mode already stable) guarantees a finite-cost policy exists, and detectability (every unobservable-through- mode already stable) guarantees the stabilizing solution is unique. The standard proof shows the Riccati map is a monotone contraction on the positive-semidefinite cone; see Lewis et al. (2012) and Bertsekas (2017) .
Continuous time. The same logic in continuous time replaces the recursion by the Hamilton–Jacobi–Bellman equation , whose Hamiltonian adds the stage cost to the cost-to-go’s rate of change along the dynamics. Its quadratic solution gives the continuous algebraic Riccati equation , with gain and Hurwitz closed loop . The HJB equation is the continuous-time Bellman equation; Chapter 1’s HJB aside lands exactly here. Note the kinship with Week 12: drop the control term and the ARE is the Lyapunov equation — optimal control is stability analysis with a cost-shaping term.
The bridge to Chapter 1
This is the chapter the curriculum has been pointing at. Lay the two equations side by side:
- Chapter 1 (general MDP). , solved by value iteration, which converges because is a -contraction.
- Chapter 13 (linear-quadratic). , solved by the Riccati recursion, which converges because the Riccati map contracts on the PSD cone.
They are the same equation — minimize immediate cost plus optimal cost-to-go — under one specialization: linear dynamics and quadratic cost keep quadratic, collapsing the infinite-dimensional functional fixed point to the finite matrix . Value iteration Riccati recursion; the Bellman operator the Riccati map; the -contraction that gave Chapter 1 its convergence the stabilizability/detectability that gives the ARE its unique stabilizing solution. Control theory reached the Riccati equation from the calculus of variations and Pontryagin’s principle Kalman (1960) ; reinforcement learning reached value iteration from the Bellman equation; LQR is where the two derivations meet on one object.
LQG: optimal output feedback, and its fragility
Real systems are noisy and only partially measured: , with Gaussian . The linear-quadratic-Gaussian (LQG) problem minimizes the expected quadratic cost. Its solution is the separation principle: run a Kalman filter Kalman (1960) to produce the optimal state estimate , then apply the LQR gain to the estimate, — estimator and regulator designed independently and combined. By W12 duality the filter gain solves the dual Riccati equation, so LQG is two Riccati solves on dual systems.
The catch is robustness. Doyle (1978) — a one-page paper — shows LQG has no guaranteed stability margins: there are LQG designs an arbitrarily small gain perturbation destabilizes.
The full-state LQR loop has a guaranteed gain margin and at least phase margin: scaling the optimal gain by any leaves stable. The LQG (output-feedback) loop has no such guarantee — its gain margin can be made arbitrarily small.
The companion reproduces this: the LQR loop stays stable across a wide gain scaling (), while the LQG loop on the same plant is stable only at the nominal — an arbitrarily small gain error on either side destabilizes it. The lesson is foundational for the rest of the curriculum: optimality on the nominal model does not imply robustness. The separation principle is optimal and fragile at once — the gap that robust control, and later robust/risk-aware RL, exist to close.
What’s next
- Week 14 (nonlinear control). Lyapunov design and feedback linearization for systems where the linear model is only a local picture. The Lyapunov function of Week 12 becomes a design tool rather than an analysis certificate, and the quadratic value function of this chapter becomes a local approximation to a nonlinear cost-to-go — the entry to nonlinear optimal control and, eventually, model predictive control (Week 15).
Exercises
-
(Derive) Starting from the Bellman optimality equation with , complete the square in to derive the gain and the Riccati recursion for .
Solution
Expanding gives . The -Hessian , so the minimizer is . Back-substitution yields with .
-
(Compute) Solve the scalar infinite-horizon LQR: , , , (all scalars). Write the DARE for and solve it.
Solution
The DARE is , a quadratic in . Clearing the denominator gives ; the positive root is the stabilizing , and . As a check, with the state already dies in one step and , .
-
(Prove) Show the optimal LQR cost from is exactly , and that under the stationary gain the cost-to-go is non-increasing along the closed-loop trajectory.
Solution
By Theorem 13.1, is the minimum cost. Along the closed loop , the DARE rearranges to , so decreases by exactly the stage cost each step — is a Lyapunov function for the optimal closed loop, tying back to Week 12.
-
(Implement) In the companion, verify the DARE residual is zero, the gain matches
control.dlqr, the finite-horizon Riccati converges to the ARE solution as grows, and the simulated closed-loop cost equals .Solution
See
experiments/python/week13/test_lqr.py:dare_gainsolves the DARE (scipy.linalg.solve_discrete_are) with residual and gain agreeing withcontrol.dlqr; the backward recursion’s converges to that as ; and the summed stage cost under matches . -
(Extend) Reproduce the LQG margin failure. Build the LQR loop and the LQG loop (LQR gain on a Kalman estimate) for the same plant, scale the loop gain by , and compare the stable range of .
Solution
See the companion’s Doyle example: the full-state loop stays stable for all (Prop. 13.1), but the output-feedback closed loop is stable only at — an arbitrarily small perturbation either way destabilizes it (the gain error multiplies only the control reaching the plant, not the commanded control the filter propagates). Optimality of the estimator-plus-regulator does not transfer to a robustness guarantee.
-
(Extend) Using Week-12 duality, show the steady-state Kalman filter gain solves the same algebraic Riccati equation as LQR on the dual pair . When does the separation principle stop being optimal (as opposed to merely stable)?
Solution
The filter error covariance solves , which is the DARE of Theorem 13.2 with . Separation is optimal precisely for linear dynamics, Gaussian noise, and quadratic cost; it loses optimality once the dynamics are nonlinear, the noise non-Gaussian, or the cost non-quadratic — where estimation and control no longer decouple (a recurring theme in model-based RL).
Companion code
The Week-13 companion lives at experiments/python/week13/ (Python, on scipy.linalg +
numpy, cross-checked against python-control).
lqr.py— the finite-horizon backward Riccati recursion; the infinite-horizon gain via the discrete and continuous algebraic Riccati equations (solve_discrete_are,solve_continuous_are); a closed-loop cost simulator; and the Doyle LQG margin-failure example (LQR gain margin vs. the output-feedback loop’s vanishing margin).test_lqr.py— mathematical-correctness tests: the DARE/CARE residuals vanish; the gain equalscontrol.dlqr/control.lqr; the finite-horizon converges to the ARE solution as ; the simulated optimal cost equals ; the closed loop is Schur/Hurwitz; and the LQR gain margin contains while the LQG loop is destabilized near .
# LQR/LQG algorithms + correctness tests (scipy + python-control cross-check)
PYTHONPATH=. pytest experiments/python/week13/test_lqr.py -q
# worked finite/infinite-horizon LQR + the Doyle LQG margin demonstration
PYTHONPATH=. python experiments/python/week13/lqr.py --doyleNonlinear Control: Lyapunov Design, Feedback Linearization, and Sliding Modes
When the plant is nonlinear, eigenvalues and Riccati equations describe only a local picture. This chapter builds the tools that replace them: Lyapunov's direct method and LaSalle's invariance principle as global stability certificates, feedback linearization that cancels the nonlinearity by coordinate change, sliding-mode control that enforces a surface in finite time and is robust to matched uncertainty, and input-to-state stability and backstepping as the constructive bridge to robust and adaptive design — with the Lyapunov function read as the control-theoretic cousin of the reinforcement-learning value function.
Nonlinear Control: Lyapunov Design, Feedback Linearization, and Sliding Modes
Where we are. Weeks 11–13 lived in the linear world: a state-space model, the structural tests of controllability and observability, and the linear-quadratic regulator that solved the optimal-control problem in closed form. Every one of those tools is, at bottom, an eigenvalue statement — stability is the spectrum of , the LQR closed loop is Schur because the Riccati matrix makes it so. But the linear model is only the tangent picture at one operating point. A pendulum, a quadrotor, a robot arm, a power grid: linearize and you get a local certificate that says nothing about the basin of attraction, the swing-up, or behavior far from equilibrium. This chapter asks the Week-14 question: what replaces eigenvalues and Riccati equations when the plant is genuinely nonlinear? The answer is a shift from spectra to energy — from “where are the poles” to “does a scalar certificate decrease along every trajectory.”
Why the linear tools run out
A nonlinear system , , linearized at the origin gives with . Lyapunov’s indirect method says: if (closed-loop) is Hurwitz, the origin is locally asymptotically stable — and that is all it says. It is silent on how large the basin is, blind to multiple equilibria and limit cycles, and useless when the linearization is marginal (eigenvalues on the imaginary axis), which is exactly when nonlinear terms decide stability. The pendulum makes this concrete: about the hanging equilibrium the linearization is a lightly damped oscillator, but the global behavior — every release angle spiraling to rest — is a nonlinear, energy statement the eigenvalues cannot certify. We need a tool that sees the whole state space at once.
Lyapunov’s direct method
The idea is mechanical-energy made abstract. Find a scalar that is zero only at the equilibrium and decreases along trajectories; then trajectories cannot escape its sublevel sets, and if the decrease is strict they slide down to the equilibrium. No solution of the differential equation is required — the certificate is checked by differentiation alone.
The origin of , , is stable (in the sense of Lyapunov) if for every there is a such that implies for all ; asymptotically stable if it is stable and for all near the origin; and globally asymptotically stable if that holds for every .
Let be continuously differentiable on a neighborhood of the origin, positive definite ( and for ), with derivative along the flow . If on the origin is stable; if for it is asymptotically stable; and if additionally is radially unbounded ( as ) it is globally asymptotically stable.
Fix and a ball . Let by positive definiteness, and choose so that on . Since , is non-increasing, so a trajectory starting inside has for all and can never reach the shell — stability. If strictly, is a decreasing function bounded below by , hence convergent; its limit must be a point where , which is only the origin — asymptotic stability. Radial unboundedness makes every sublevel set compact, so the argument is global.
The pendulum is the worked example. Take the energy , positive definite about the hanging equilibrium. Along the damped dynamics its rate is — negative semidefinite, not definite, because it vanishes on the whole line , not just at the origin. Theorem 14.1 then gives only stability, not asymptotic stability, even though we know every trajectory decays. The gap is closed by an invariance argument Khalil (2002) .
Let be a compact set, positively invariant under , and let be continuously differentiable with on . Then every trajectory starting in converges to the largest invariant set contained in .
For the damped pendulum is ; the only complete trajectory that stays there is the equilibrium (if then forces ), so LaSalle upgrades stability to asymptotic stability with a semidefinite . The companion confirms it: energy decreases monotonically and the state converges to the origin.
The bridge to Chapters 1 and 13. A Lyapunov function is a value function read backwards. Chapter 1’s satisfies the Bellman equation and decreases in expectation under an improving policy; a Lyapunov decreases along every deterministic trajectory, — the autonomous, worst-case analog of “the value goes down.” Chapter 13 fused the two: there we proved drops by exactly the stage cost each step, so the optimal cost-to-go is a Lyapunov function. The difference is where the certificate comes from. Optimal control solves the whole Hamilton–Jacobi–Bellman problem and gets as a byproduct; Lyapunov design guesses (often a physical energy) and only checks a derivative — cheaper, structure-exploiting, and not tied to optimality.
Feedback linearization
Lyapunov’s method certifies; feedback linearization constructs a controller by canceling the nonlinearity outright. For an input-affine system with output , differentiate until the input appears.
The system has relative degree at if for near and , where the Lie derivative is the rate of change of along . Equivalently, is the number of differentiations of before the input appears explicitly.
When the relative degree equals the state dimension, the change of coordinates turns the system into a chain of integrators, and the control
makes the input–output map exactly linear, — then place poles with a linear Sastry (1999) . The pendulum is the textbook case of computed torque: with , choosing cancels gravity and damping, leaving ; then gives a chosen second-order linear closed loop Slotine & Li (1991) .
Under the computed-torque law above, the nonlinear closed loop equals the linear system exactly, with closed-loop poles the roots of . Stability is by design (choose ), not by linearization.
The companion integrates the true nonlinear plant under this law and the target linear system from the same initial state and finds the trajectories identical to numerical precision — the nonlinearity is gone, not merely small. The cost is honesty about its price: feedback linearization needs an accurate model (it cancels exact terms), it can demand large control authority, and it is only valid where the relative degree is well-defined and the internal dynamics (the unobserved part when ) are stable. Cancel a nonlinearity you do not know precisely and the cancellation leaves a residual — which motivates a method that does not depend on exact cancellation.
Sliding-mode control
Sliding-mode control trades smoothness for robustness. Instead of canceling the dynamics, it forces the state onto a designer-chosen surface and keeps it there despite model error, as long as the uncertainty enters through the same channel as the control (matched uncertainty).
Let define a sliding surface on which the reduced dynamics are stable, and suppose the control enforces the reaching law with . Then , so reaches in finite time bounded by , after which the trajectory stays on and the reduced dynamics carry it to the origin.
For the pendulum, take (); on the reduced dynamics are , which decays. The control drives into a boundary layer of width . The robustness is the selling point: a wrong gravity estimate still drives , because the gravity term enters through the same input channel as and is dominated by a large enough Slotine & Li (1991) . The companion verifies all three claims — finite-time reaching within the bound, the surface maintained inside the boundary layer thereafter, and convergence under a deliberately mismatched model.
Lyapunov is doing the work both times. Computed torque imposes a stable linear Lyapunov function; sliding mode uses as a Lyapunov function for the surface. Each design is a recipe for a certificate — which is exactly what the next two ideas systematize.
Input-to-state stability and backstepping
Real systems have disturbances. Input-to-state stability (ISS) is the right generalization of asymptotic stability to forced systems, and it is stated with comparison functions: a class- function is continuous, strictly increasing, and zero at zero.
The system is input-to-state stable if there exist a class- function and a class- function such that for every initial state and every bounded input,
The state is eventually bounded by a gain of the input size, and decays to zero when the input does.
ISS, due to Sontag, makes “small disturbance, small deviation” precise and composable: a cascade of ISS subsystems is ISS, which is what lets large nonlinear designs be built and certified piece by piece Sontag (1998) . Backstepping is the constructive engine that exploits this. For systems in strict-feedback (cascade) form, it builds the controller and a Lyapunov function recursively: stabilize the first subsystem treating the next state as a virtual control, define the error between that state and its desired value, augment the Lyapunov function with a quadratic in the error, and step inward until the real input appears Kellett & Braun (2023) . The output is a controller and a Lyapunov certificate delivered together — Lyapunov design turned into an algorithm, and the classical counterpart of the “value function as a learnable object” that model-based RL will pursue in Part III.
Nonlinear control versus deep RL
Lay the chapter beside the reinforcement-learning half of the curriculum. Both seek a feedback policy and a scalar certificate of good behavior; they differ in what they assume and what they pay.
- Nonlinear control assumes a model with structure — input-affine form, a known relative degree, matched uncertainty, a physical energy. Given that structure, it returns a controller with a stability proof and no sampling: computed torque, a sliding surface, a backstepping Lyapunov function. The certificate is designed, not learned.
- Deep RL assumes samples, not structure. It learns and from interaction, paying in data and variance, and buys the ability to handle dynamics no one can write down — contact, friction, pixels — where relative degree and clean cancellations do not exist.
The dividing line is whether the structure is available and trustworthy. When it is, control wins on guarantees and sample cost; when the structure is absent or too hard to obtain, sampling wins on reach. Part III is the synthesis: model predictive control (Week 15) turns a model into a policy by online optimization, and the convergence weeks graft learned value functions onto controllers with Lyapunov-style guarantees — RL’s reach with control’s certificates.
What’s next
- Week 15 (model predictive control). Rather than design one feedback law, re-solve a finite-horizon optimal control problem at every step and apply the first move. MPC is online approximate dynamic programming: Chapter 13’s Riccati value function becomes a horizon- optimization, the Lyapunov certificate of this chapter reappears as a terminal cost, and constraints — which neither LQR nor feedback linearization handle — become first-class.
Exercises
-
(Derive) For the hanging pendulum with energy and dynamics , compute and show the gravity terms cancel, leaving .
Solution
and . Their inner product is . The cross terms cancel; only dissipation remains. For this is negative semidefinite, so Theorem 14.1 gives stability and LaSalle (Theorem 14.2) upgrades it to asymptotic stability.
-
(Prove) Show that for implies the limit of is a value at which , and conclude the origin is asymptotically stable.
Solution
is monotonically decreasing and bounded below by , hence convergent to some . If the trajectory stays in the compact shell where , forcing — a contradiction. So , and by positive definiteness . (This is the strict-decrease half of Theorem 14.1; LaSalle handles the semidefinite case.)
-
(Compute) A system has relative degree : , , . Find the feedback-linearizing control that imposes and give the closed-loop poles.
Solution
, so with yields . The Lie-derivative bookkeeping: , , (relative degree ). Poles are the roots of ; pick for a Hurwitz pair.
-
(Prove) For the reaching law , show hits zero by time . Why does matched uncertainty not change this bound?
Solution
With , . Separating, decreases at constant rate , so reaches in time . A matched disturbance enters as ; choosing keeps , so the surface is still reached — the gain dominates the uncertainty rather than canceling it.
-
(Implement) In the companion, verify the three sliding-mode claims: finite-time reaching within , the surface maintained in the boundary layer afterward, and convergence under a mismatched model.
Solution
See
experiments/python/week14/test_nonlinear.py:test_sliding_mode_reaches_surface_in_bounded_timechecks the reaching bound and boundary-layer maintenance;test_sliding_mode_robust_to_matched_parameter_errorbuilds the controller with a wrong length (so a wrong gravity coefficient) yet still reaches the surface and converges — matched-uncertainty robustness. -
(Extend) Argue why the quadratic LQR cost-to-go of Chapter 13 is a Lyapunov function for the optimal closed loop, and use this to connect Lyapunov design to value functions.
Solution
From Chapter 13, along the optimal closed loop , so is positive definite with — a Lyapunov function that also equals the optimal value. Lyapunov design chooses such a certificate directly (energy, , a backstepping sum) instead of solving the optimal-control problem for it — the same object, reached without the full Hamilton–Jacobi–Bellman computation. This is the seam model-based RL works along in Part III.
Companion code
The Week-14 companion lives at experiments/python/week14/ (pure numpy, RK4 integration with the
controller evaluated at each stage for a faithful continuous-time closed loop).
nonlinear.py— the pendulum model (hanging and upright conventions); the energy Lyapunov function with its analytic and numeric ; a certificate check that passes for the damped pendulum and fails for the anti-damped one; the computed-torque feedback-linearizing law and its target linear system; and the boundary-layer sliding-mode law with the sliding surface and reaching time.test_nonlinear.py— mathematical-correctness tests: matches the numeric ; the certificate discriminates damped from anti-damped; the damped pendulum’s energy is monotone and the state converges (LaSalle); feedback linearization reproduces the target linear system exactly with the prescribed poles; and sliding mode reaches the surface in bounded time, stays in the boundary layer, and is robust to matched parameter error.
# nonlinear-control algorithms + correctness tests
PYTHONPATH=. pytest experiments/python/week14/test_nonlinear.py -q
# worked Lyapunov / feedback-linearization / sliding-mode demonstrations on the pendulum
PYTHONPATH=. python experiments/python/week14/nonlinear.py