Function Approximation and the Deadly Triad
Replacing the value table with a parametric approximator: linear value functions, semi-gradient TD, and the projected Bellman operator. Why on-policy semi-gradient TD converges to a bounded-error fixed point, and why function approximation, bootstrapping, and off-policy training together can diverge — the deadly triad, witnessed by Baird's counterexample.
On this page
Function Approximation and the Deadly Triad
Where we are. Every method so far stored one number per state in a table. That ends the moment the state space is large or continuous: we must approximate the value function with a parametric model and let it generalize across states. This chapter is the first where the clean contraction story of Chapters 1–4 breaks. Two results frame it. On-policy, semi-gradient TD still converges — but to a projected fixed point whose error is the representation’s projection error, amplified by : approximation changes the fixed point itself. Off-policy, the same update can diverge. The combination that breaks is named the deadly triad — function approximation, bootstrapping, and off-policy training — and Baird’s counterexample is its sharpest witness.
Linear approximation and semi-gradient TD
Replace the table with a parametric . We focus on the linear case, where a feature map () gives
The representable value functions form a -dimensional subspace of , where stacks the feature rows. Learning now adjusts , and a value learned at one state moves the values of all states sharing features — generalization, the whole point.
Given a transition , semi-gradient TD(0) updates
It is called semi-gradient because it treats the bootstrap target as fixed — it does not differentiate the target with respect to , so the update is not the true gradient of any fixed objective.
That last point is the crux of the chapter. A true-gradient method on a fixed loss cannot diverge to infinity; semi-gradient TD can, because the “target” it descends toward moves with .
The projected Bellman operator
Where does semi-gradient TD converge, when it does? Not to — that generally leaves the representable subspace and is not expressible as any . The update implicitly projects it back.
Let be a distribution over states and the weighted inner product, with norm . The projection maps a value function to the nearest representable one, . The TD fixed point is the satisfying
the fixed point of the composed projected Bellman operator .
Semi-gradient TD is a stochastic-approximation scheme (Chapter 4) for this fixed point: in expectation, under the state-visitation distribution its update drives toward . Whether that iteration converges hinges entirely on whether is a contraction — which depends on .
When it works: on-policy convergence
Let be the on-policy stationary distribution of (so ). Then is a -contraction in , and is nonexpansive in , so is a -contraction with a unique fixed point . Its error is the projection error, amplified by the horizon:
Two facts compose. (i) Under the stationary , the transition operator is nonexpansive in :
Since , this gives . (ii) is an orthogonal projection in , hence nonexpansive. So is a -contraction and has a unique fixed point (Banach, Ch. 1). For the bound, since we have , so
With the triangle inequality , substitute and solve to get the stated bound.
Two readings. First, convergence is conditional: it rests on being the on-policy distribution, the one fact that makes nonexpansive. Second, the fixed point moved: even at convergence the error is the projection error — what the feature space cannot represent — blown up by . With a table the projection error is zero and we recover exactly; with a poor feature space the fixed point can be far from . Tsitsiklis and Van Roy Tsitsiklis & Van Roy (1997) established exactly this convergence and bound for on-policy linear TD.
The deadly triad
Proposition 5.1 needed all three of its ingredients to be benign. Drop the on-policy assumption and the guarantee collapses. The instability requires the conjunction of three elements, each harmless alone — the deadly triad Sutton & Barto (2018) :
- Function approximation — a value model with fewer parameters than states.
- Bootstrapping — TD/DP targets that reuse current estimates (vs. Monte Carlo’s full returns).
- Off-policy training — updating from a distribution other than the policy’s own.
Any two are safe: tabular off-policy bootstrapping is Q-learning (Chapter 4, convergent); on-policy bootstrapping with approximation is Proposition 5.1; Monte Carlo with approximation and off-policy data is a genuine gradient method and is stable. All three together can make — now with the wrong (off-policy) distribution — an expansion, and the parameters diverge to infinity. Baird Baird (1995) built the canonical witness.
Seven states, a linear feature map of dimension eight, and zero reward everywhere — so is trivially representable (). The target policy always takes the “solid” action (to the seventh state); the behaviour policy explores all states (off-policy). Off-policy semi-gradient TD with uniform state weighting applies a linear update whose matrix has an eigenvalue with positive real part. The weights diverge geometrically even though a perfect, zero-error solution sits at the origin.
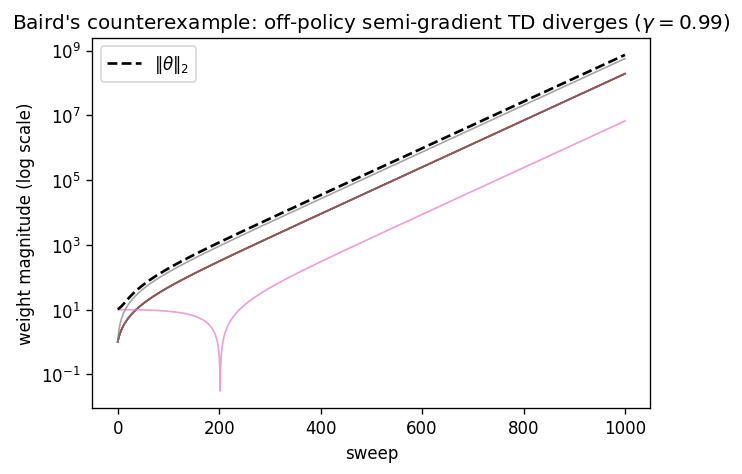
The lesson is not that approximation is hopeless but that the interaction is what bites: the projected operator’s contraction was an on-policy privilege, and off-policy data revokes it. The next chapter’s engineering — target networks and replay — exists precisely to tame this instability well enough to train deep off-policy value functions in practice.
Beyond semi-gradient: LSTD and true-gradient methods
Two routes around the difficulty are worth naming. Least-squares TD (LSTD) solves the linear TD fixed-point equations directly: accumulate and , then set — no step size, far more sample-efficient per datum, converging to the same on-policy fixed point as Proposition 5.1. Gradient-TD methods (GTD, TDC) instead descend a true objective (the projected Bellman error), restoring convergence even off-policy at the cost of a second set of weights. Both are the subject of the roadmap’s extension; LSTD appears in the companion.
The dynamic-programming bridge
Function approximation is the first crack in the contraction spine. Chapters 1–4 chased the unique fixed point of a -contraction; here the object becomes , and its fixed point both moves (by the projection error) and, off-policy, may not exist as a stable limit at all. Two bridges forward:
- To control (LQR, Ch. 13). The linear-quadratic regulator is the lucky case where the optimal value is exactly quadratic — representable with zero projection error — so the approximation never bites and the Riccati recursion converges cleanly. Most of control’s tractable cases are exactly this: a function class the true value lives inside.
- To deep RL (Week 6). DQN keeps bootstrapping, off-policy data, and a (nonlinear) approximator — the full triad — and survives by engineering the instability down: a slowly-updated target network freezes the bootstrap target, and experience replay decorrelates and re-weights the update distribution toward something tamer.
What’s next
- Week 6 builds DQN: the replay buffer and target network as direct countermeasures to the deadly triad, scaling approximate value learning to pixels.
Exercises
-
(Derive) Write the semi-gradient TD(0) update for linear and show it is not the gradient of . Identify the missing term.
Solution
. Semi-gradient TD uses (ascending ), dropping the term from differentiating the target. The dropped term is exactly what would make it a true gradient — and what, when present (residual-gradient methods), changes the fixed point and the stability.
-
(Prove) Show is a -contraction in when is the on-policy distribution, and derive the projection-error bound (Prop. 5.1).
Solution
is a -contraction in because is nonexpansive under the stationary (Jensen + ); is nonexpansive as an orthogonal projection; the composition is a -contraction. The bound follows from and the triangle inequality, as in the proof above.
-
(Compute) In Baird’s setup the update is . What property of (or of ) causes divergence, and why does a small not prevent it?
Solution
Divergence occurs iff has spectral radius , i.e. has an eigenvalue with positive real part (for small , exactly then). Shrinking only slows the geometric blow-up; it cannot flip the sign of the unstable eigenvalue. The companion computes ‘s spectrum.
-
(Implement) Verify on the companion that on-policy semi-gradient TD converges to (near) on the random walk, while off-policy semi-gradient TD on Baird’s counterexample diverges (the committed figure).
Solution
See
experiments/python/week05/test_fa.py: on-policy semi-gradient TD with tabular-complete features matchesdp.policy_evaluationwithin a sampling tolerance and keeps bounded weights; Baird’s off-policy update grows the weight norm without bound (the divergence the figure plots). -
(Extend) Implement LSTD and confirm it recovers the same on-policy fixed point as semi-gradient TD (and exactly when the features are tabular-complete).
Solution
LSTD solves with , ; its solution is the TD fixed point. With tabular-complete features the projection error is zero and reproduces , which the companion’s
lstdasserts against the Week-1 linear solve.
Companion code
The Week-5 companion lives at experiments/python/week05/ and reuses the Week-3
random walk and the Week-1 dp.policy_evaluation oracle. It is the chapter’s two
poles side by side: a convergent on-policy method and a divergent off-policy one. (The
roadmap suggests tile coding on MountainCar-v0; the random walk is used here because it
has a closed-form to test against — MountainCar tile-coding is a
natural deferred showcase that lacks an exact oracle.)
fa.py— linearsemi_gradient_td(constant step size with Polyak–Ruppert averaging) andlstdfor a generic(P, R, policy)with an arbitrary feature matrix . Pure NumPy.baird.py— Baird’s seven-state counterexample: builds the feature matrix and the off-policy expected-update matrix , iterates to divergence, and (with--plot) renders the committed divergence figure.test_fa.py— mathematical-correctness tests: on-policy semi-gradient TD converges to the analytic (and stays bounded); LSTD recovers with tabular-complete features; and Baird’s off-policy update diverges (the weight norm grows without bound while has an unstable eigenvalue).
# core algorithms + correctness tests (pure NumPy, no Gymnasium needed)
PYTHONPATH=. pytest experiments/python/week05/test_fa.py -q
# regenerate the committed Baird divergence figure
PYTHONPATH=. python experiments/python/week05/baird.py --plot